

 > 新闻中心 > 评测室
> 新闻中心 > 评测室

英伟达2020年5月14号发布的基于新架构的A100加速计算卡,根据官方宣传:自动混合精度和FP16,可以为A100带来2倍的性能提升;
而且,在不更改代码的情况下,具有TF32的A100与英伟达Volta相比,性能能够高出整整20倍!
那么,A100与V100相比,这两款显卡究竟有多大差距呢?一起来看看。

△ 英伟达A100 GPU
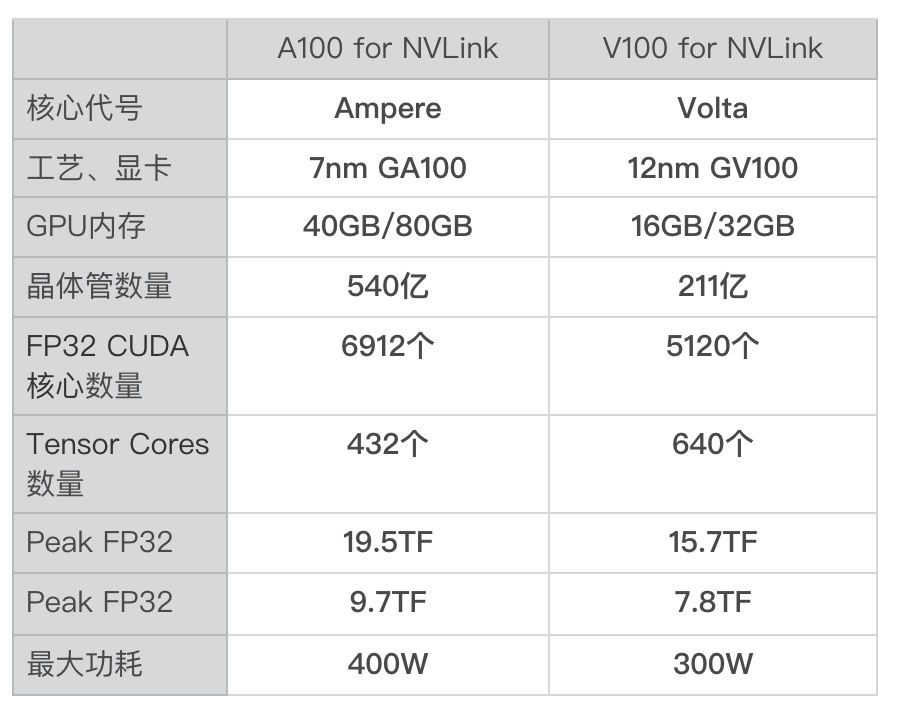
相比V100,A100的单精度浮点计算能力,从15.7TFLOPS提升至19.5TFLOPS;而双精度浮点运算从7.8TFLOPS提升至9.7TFLOPS。
在英伟达的公开信息中,列出了A100与V100的参数对比:
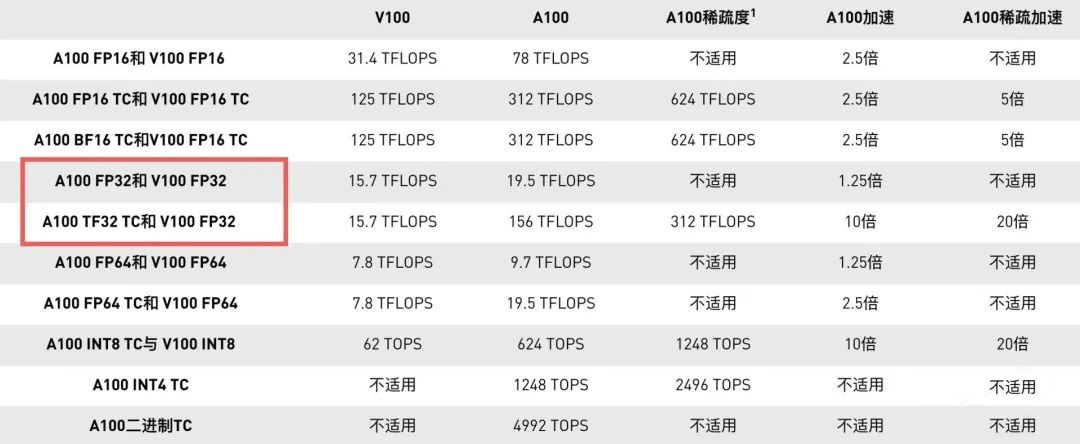
在BERT深度学习训练中,两款显卡的速度对比:

在其他训练模型下,A100是否能有同样出色的表现?
两款显卡均选择适用于NVLink的产品进行测试,在32位精度下,采用PyTorch训练。
对于A100,32位是指FP32+TF32;对于V100,指的是FP32。
测试分为两部分:卷积神经网络训练速度、语言模型训练速度。
我们将一块V100的32位的训练速度归一化,对比了不同数量GPU的训练速度。
得到结果:
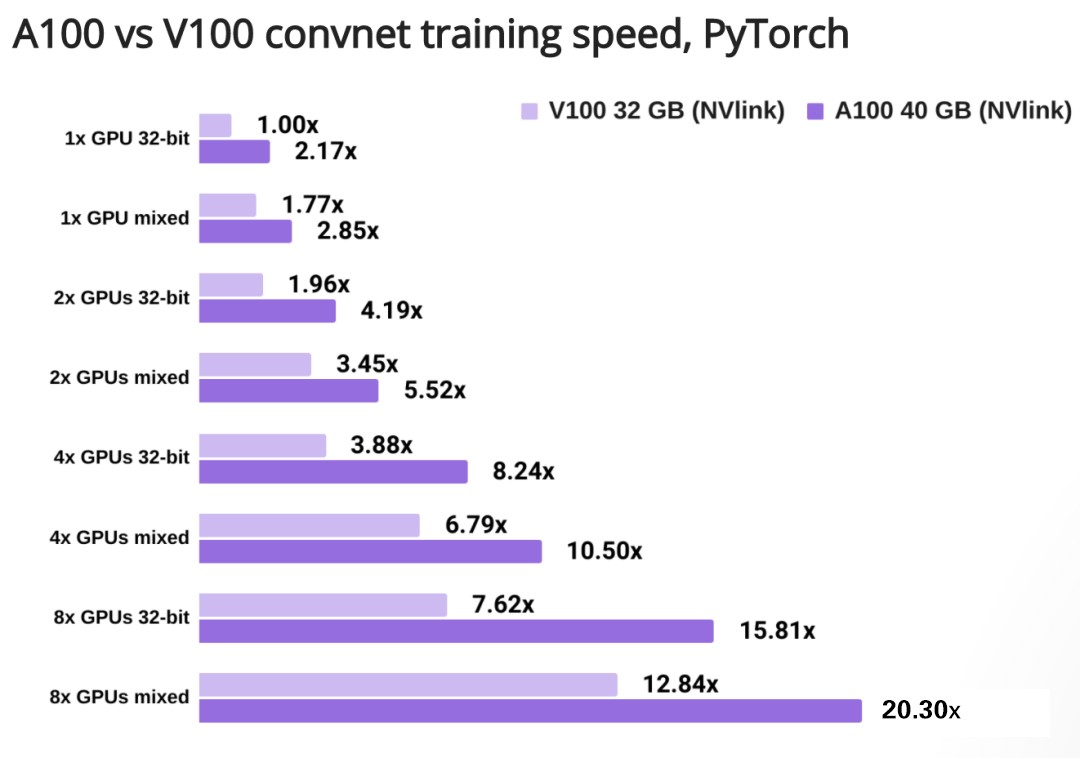
1块A100 VS 1块V100,进行32位训练:前者速度是后者的2.17倍;
4块V100 VS 1块V100,进行32位训练:前者速度是后者的3.88倍;
8块A100的混合精度训练 VS 1块V100的32位训练:前者速度是后者的20.35倍。
与上面的对比方法相同。
将结果在Transformer-XL base、Transformer-XL large、Tacotron 2和ERT-base SQuAD上取平均值。
得到结果:
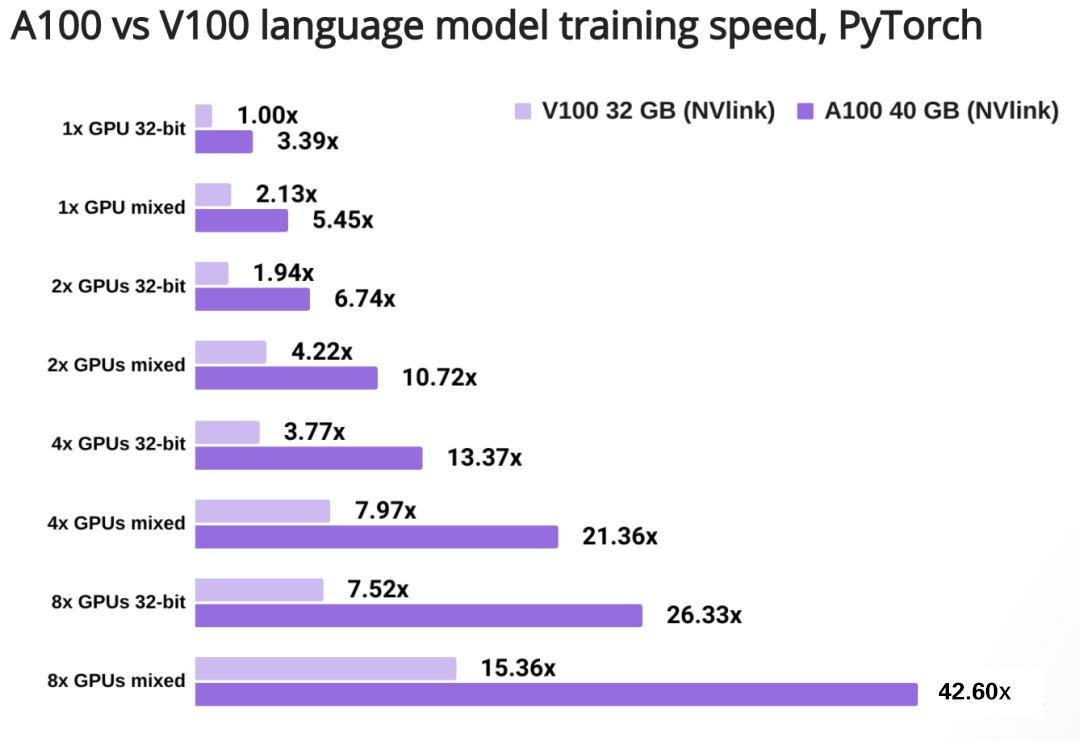
例如:
1块A100 VS 1块V100,进行32位训练:前者速度是后者的3.39倍;
4块V100的混合精度训练 VS 1块V100的32位训练:前者速度是后者的7.97倍;
8块A100的混合精度训练 VS 1块V100的32位训练:前者速度是后者的42.60倍。
在卷积神经网络训练中:
1块A100的训练速度是1块V100的2.2倍;
使用混合精度时,前者则是后者的1.6倍。 在语言模型训练中:
1块A100的训练速度是1一块V100的3.4倍;
使用混合精度时,前者则是后者的2.6倍。
 渝公网安备 50010702500475号
渝公网安备 50010702500475号