全新视觉盛宴 Fermi架构Quadro显卡横评

在本次横评之前,我们首先要了解的是什么是Fermi架构。只有了解了这个架构,才能够对下面的测试数据及显卡本质有了深刻的认识。也正因为如此,我们将耗费大量的笔墨讲解Fermi架构的好处。当然,这些内容看起来似乎并不那么容易理解。
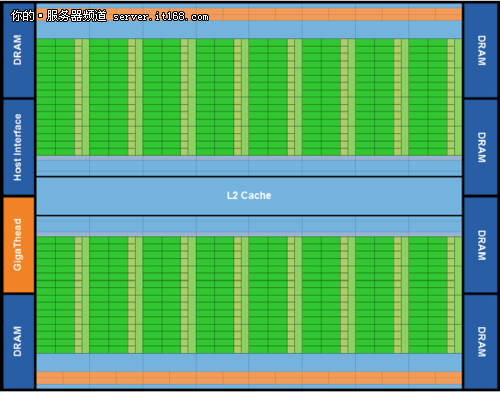
Fermi CUDA计算架构
Fermi架构是继G80架构之后的又一重要的GPU架构。G80架构在时nvidia公司最初的通用计算GPU架构,既可以做图形计算,也可以用来做并行计算。GT200架构扩展了G80架构的特点和功能。对于Fermi而言,是Nvidia公司总结G80和GT200架构以后,几乎是重新设计的专门针对于通用计算的GPU架构。Fermi的设计采纳了用户在使用G80和GT200架构时候给出的建议。Fermi的主要设计针对于以下几点:
单精度的计算大概是桌面CPU的10倍的时间左右,并且一些应用需要GPU提供更强的双精度运算。
ECC的添加,使得内存有容错的能力。
有些并行计算并不一定能使用到shared memry,所以更多的需求是在内存访问中加上缓存。
有些CUDA程序需要超过16KB的SM shared memry来加速他们的运算。
用户需要更快的应用程序和图形显示之间的资源切换。
用户需要更快的原子读写操作来加速并行程序运算。
根据以上的需求,Fermi的设计团队通过新的架构设计增加了它的计算能力,并且支持更好的可编程能力和计算效果。Fermi的主要的架构更新如下:
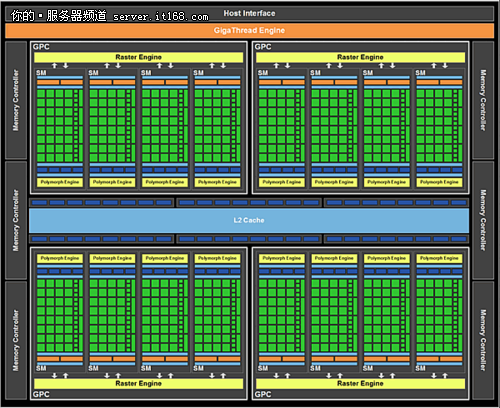
Fermi图形渲染架构
第三代的Streaming Multiprcessr
每个SM包含32个CUDA计算cre,是GT200的4倍
8倍于GT200的双精度浮点计算
Dual Warp调度策略,可以使得在一个时钟周期内同时启动两个warp进行计算
64KB的RAM支持可配置的shared memry和L1缓存
第二代的线程并行计算ISA架构
统一的地址空间,完整的支持C++特性
针对penCL和DirectCmpute做了优化设计
完整支持IEEE 754?2008 32bit 和64bit 精度
通过分支预测来增强计算能力
增强的内存操作子系统
Nvidia的并行数据缓存,支持L1和L2的可配置能力
第一个支持GPU内存的ECC
增强了内存原子操作能力
NVIDIA千兆线程引擎
10倍的上下文切换能力
并发的kernel执行
支持blck乱序执行
双重叠的内存访问引擎
第一块Fermi GPU只用了30亿个晶体管,包含512个有CUDA计算能力的core。每一个CUDA core可以在一个时钟周期里面执行一次浮点数运算或者一次整数运算。512个core分别分布在16个SM里面,每一个SM里面包含32个core。包含6个64位的内存partition,有384bit的内存带宽,支持最多6GB的GDDR5 DRAM。通过PCIE和CPU进行链接。千兆线程管理器会自动管理线程调度到不同的SM上进行运行。

Fermi架构第三代流处理器群示意图
第三代的SM架构不只是增强了SM的计算能力,同时使得可编程性和效率得到提高。每一个SM都包含32个CUDA计算核心,每一个核心都有完整的整数计算单元和浮点数计算单元。以前的GPUs都是用IEEE 754-1985的单精度浮点标准。Fermi采用的是IEEE 754-2008的单精度浮点标准,单精度和双精度都同时支持FMA功能FMA是通过MAD来完成乘法和加法操作,同时保证没有精度的损失。FMA的精确计算能力超过了通过指令分解来完成的同样的工作。GT200支持了双精度的FMA。
ALU几乎采用完新的设计,支持64bit和扩展的精确的指令运算,同时支持计算,移位,布尔值,比较,转化和更多的指令操作。
16个内存存/取单元
每一个SM包含16个内存存/取单元,可以保证源和目标地址可以在一个周期内同时由16个线程来进行操作。支持缓存和DRAM的任何位置的读取。
特性函数处理单元
特性函数处理单元处理超越函数,包括sin,cosine,求倒数,平方根。每一个SFU在一个周期内每一个线程可以执行一个指令操作,每一个warp执行需要8个周期。指令分发器可以按照当前SFU的运行情况来分发指令,当一个SFU在进行运算的时候,可以将指令分发到其他的SFU处理单元。
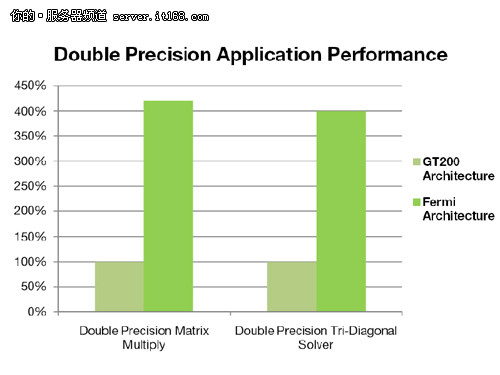
双精度的浮点计算
双精度的浮点计算在高性能计算中有着核心的重要位置,在求解线性代数中,数值计算量子化学中都会需要双精度浮点运算。Fermi架构为支持双精度浮点运算进行了特别设计每一个SM在一个时钟周期内可完成16个双精度浮点数的FMA操作。是在GT200架构以后又一激动人心的设计。
双指令发送单元
Fermi的每一个SM都有两个指令发送单元,可以同时让两个warp相互独立的并发运行。Fermi的Dualwarp调度机制可以同时并发调度两个warp的一条指令分别在16个一组的CUDAcores上进行计算,或者在16个存/取单元运行,或者4个SFU上运行。Fermi的调度器并不需要在指令流之间进行附属检查。利用如此优美的双发射调度机制,使得Fermi可以让硬件的计算能力达到极致。
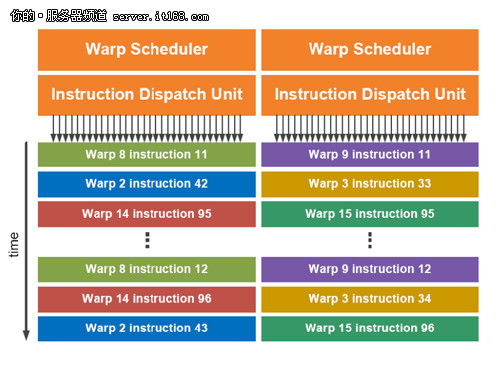
非常多的指令可以进行双发射,例如两条整数运算指令,两条浮点数运行指令,或者混合的整数,浮点,存 取,和SFU特殊处理指令都可以被并发执行。单精度和双精度的指令一样可以并发执行。
容量为64KB的共享内存与L1缓存
在核心上的共享内存对可编程性和运行效率都是强有力的支持。共享内存可以让同在一个block的线程之间进行协作,并且可以重复利用在片上的内存,来减少片外内存访问的开销。共享内存在很多高性能CUDA应用程序中都起到了关键的作用。
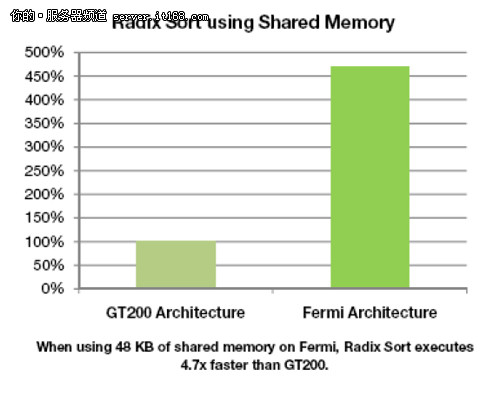
G80和GT200的每一个SM都有16KB的共享内存。在Fermi的架构中,每一个SM都有64KB的共享内存,这些内存可以被配置成48KB的共享内存和16KB的L1缓存,或者配置成为16KB的共享内存和48KB的L1缓存。
对于已经使用共享内存的程序来说,可以提供3倍的共享内存的支持,尤其是那些由于带宽引起的问题。对一些已经使用了共享内存作为缓存的应用程序来说,代码可以简化为直接使用系统硬件提供的缓存,同时还可以使用16KB的共享内存来使线程进行交互。最好的情况就是一些原本就没有使用共享内存的程序,直接利用L1缓存,可以使得CUDA程序运行需要更少的时间,得到更高的性能。
Fermi是第一个支持并行线程处理(PTX)2.0指令集的体系架构。PTX是一个底层的虚拟机和ISA架构,来支持并行运算。在程序安装的时候,PTX指令就会被GPU的驱动程序翻译为机器码。
PTX最主要的目标:
提供跨多卡GPU的稳定的ISA指令
在编译的时候使得程序达到GPU最高的性能
提供系统无关的ISA指令,可供C,C++,Fortran或者其他语言使用
提供代码分布式的ISA架构给应用程序和中间件开发者
提供通用的ISA架构,来支持不同平台上的代码的优化和转译
使得开发lib和高性能的kernel函数更加的简便
提供scalable的编程模式,可以使得程序支持不同数目cores的GPU
PTX 2.0 有一些很多新的特性,使得GPU在有更高的可编程性,更精确,和提供更高的性能。这些包括:完整支持IEEE 32bit 的单精度浮点数,统一的寻址支持变量和指针,新的指令来支持OpenCL和DirectCompute。最终刚要的是,PTX 2.0对完整支持C++做了特殊的设置??统一寻址完整支持C++。
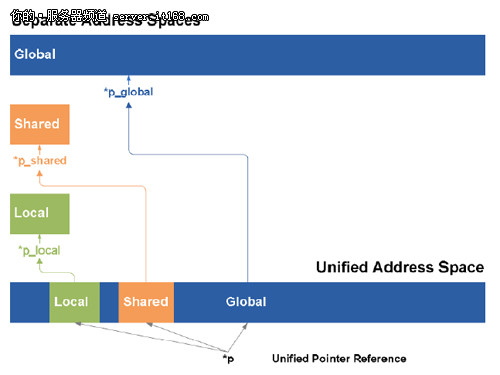
Fermi和PTX2.0ISA实现了统一寻址空间,可以统一寻址3种不同的内存地址(线程私有变量,block的共享内存和全局内存)来进行存/取操作。在PTX1.0中,存/取指令需要指定在这三种地址中那一个进行寻址,程序可以在编译的时候就知道在特定的那个地址进行寻址。这样就很难完全满足C和C++的指针在编译的时候指向不确定地址,而只有在运行的时候才知道确切地址的情况。
通过PTX2.0的统一寻址空间,让三种地址空间通过唯一的连继续的地址空间进行寻址。单一的寻址空间进行统一的存/取指令操作在这样的地址空间上,代替了在三种空间上都要进行不同存/取的方法。40bit位宽的可以支持TB的寻址空间,ISA架构可以提供64bit的位宽寻址空间,为将来的扩展提供支持。
统一地址空间的实现,可以让Fermi真正完全的支持C++编程。在C++中,所有的变量和函数都在一个object中,通过指针进行访问。PTX2.0就可以通过统一指针管理方式找到任何内存上的目标,Fermi提供的硬件寻址方式可以自动的把指针映射到正确的物理地址。
Fermi和PTX2.0ISA同样提供C++虚函数的支持,函数指针的支持,新建和删除操作动态分配目标和回收资源。C++的异常操作try和catch同样被支持。
block组织的grid,同步,同一个block里面共享内存,全局内存,还有院子操作。Fermi第三代支持CUDA的架构,很自然很好的优化支持了这些API。更特别的,Fermi利用标准的转换方式,从硬件上支持OpenCL和DirectCompute的接口指令,可以让图形计算和通用计算很简单的操作在相同的数据上。PTX 2.0 ISA同样增加了对DirectCompute的指令population count,append和bit?reverse。
OpenCL和Directcomputer和CUDA的编程模型很相近,几乎使用相同的线程,block组织的grid同步同一个block里面共享内存,全局内存,还有操作。Fermi第三代支持CUDA的架构,很自然很好的优化支持了这些API。更特别的,Fermi利用标准的转换方式,从硬件上支持OpenCL和DirectCompute的接口指令,可以让图形计算和通用计算很简单的操作在相同的数据上。PTX 2.0 ISA同样增加了对DirectCompute的指令population count,append和bit?reverse。
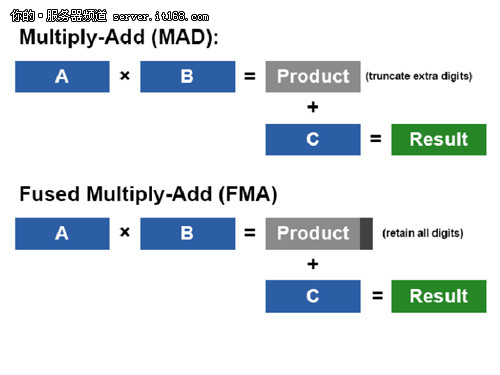
单精度的浮点数由硬件默认的支持,包括四个IEEE 754-2008支持的标准(无限趋近,零,最大值和最小值)。在浮点系统中,Subnormal是处于最大值和最小值之间的数。在较早的的GPU架构中,通常情况下把这一范围的浮点数归于0,这样一般都会损失精度或者让程序发生一些意想不到的错误。CPU通常情况下都要通过额外的软件方式来处理,一般需要上千个的周期。Fermi是通过硬件来处理subnormal浮点数,可以精确的计算小于0的浮点数而没有精度损失。
通常情况下在GPU上完成的计算,像线性代数,一些科学常用的程序,都是两个数相乘然后加上第三个数,例如:D=A*B+C。以前的GPU架构通常情况下都是利用乘加指令来完成(MAD),可以让两个操作在一个指令周期内完成。MAD指令使用了分断的乘法,然后使用了取整的加法。Fermi使用了更高精度的FMA指令,不但可以支持32bit的单精度的操作,也满足64bit双精度的需求。(GT200只支持双精度的FMA)在这样的精度保证下面,更多的算法都可以受益,像渲染算法,一些迭代的数学算法,更快的除法和求平方根的算法。
在PTX 2.0 ISA中所有指令都增加了预处理,这样可以更快更容易执行可以运行的部分。在执行if-else的时候,SM会计算每一条分支需要执行的条件,增加一个可以满足的条件,硬件都会执行那个分支。有了分支预测以后就可以更多的分支一起运行,比一条分支一条的执行会更有效果。Fermi的架构增加的条件判断隐藏了分支运算中的overhead。
通过了解不同的成千上万的应用程序,我们发现shared memory可以解决议部分程序的问题,但是不能解决所有的问题。一些应用程序天然的就需要共享内存,有些应用程序需要cache,有的既需要shared memory也需要cache。优化的内存设计可以既提供shared memory也提供cache,可以让程序员根据自己的需求来做选择。Fermi的架构可以支持两种需求。
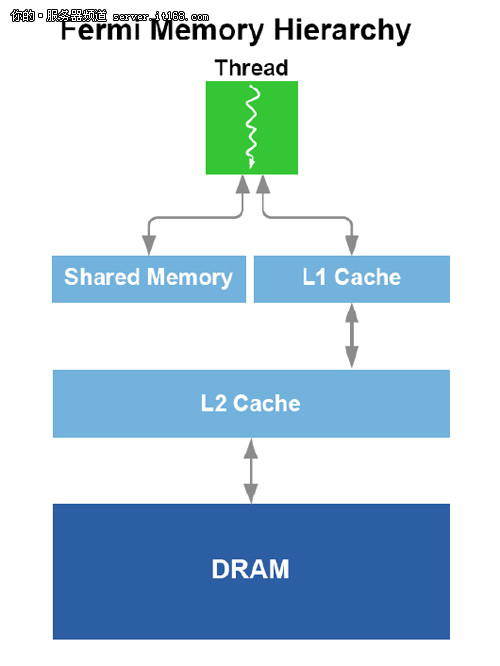
在Fermi的架构中,每个SM都包含64KB的高速RAM,可以配置为48KB的共享内存和16KB的L1缓存,也可以配置为16KB的共享内存和48KB的L1缓存。当使用48KB的共享内存的时候,程序可以动态的分配内存,(像electrodynamic的模拟)可以让程序有三倍性能的提升。有的程序访问的地址不是预先分配的,48KB的L1缓存就可以更好的支持直接访问DRAM的程序。 两种情况的配置,L1缓存都可以增加临时寄存器的使用,以避免溢出。以前的GPU架构都是直接把寄存器分配到对应的DRAM增加了访问的延迟。通过L1缓存,更好的支持了临时寄存器的使用。 Fermi有768KB的统一的L2缓存,可以支持所有的存取和纹理操作。L2缓存和所有的SM都相通。L2提供有效和高速的数据支持。有些算法不能在运行前就确定下来,像一些物理问题,光线跟踪,稀疏矩阵乘法,尤其需要缓存的支持。过滤器和转换器需要所有的SM都去读取相同数据的时候,缓存一样会有很大的帮助。
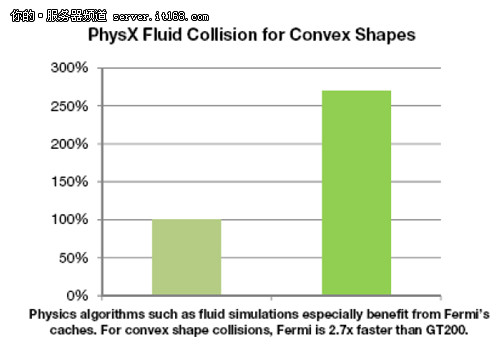
Fermi是第一款支持内存错误检查和修复(ECC)的CPU架构。在使用FPU做大数据量的处理和高性能计算的时候,ECC是有大量的需求。在医疗图像处理和大型集群中ECC是特别有需要的特性。
正常情况下的内存位的存储错误,都会引起软件的错误。ECC就是在上述错误没有多系统造成影响的情况下,用来检查和纠正这样的错误。由于这样的错误会根据系统的增大线性的增加,ECC就成为大型集群中必不可少的需求。
在进行测试之前,先来介绍一下我们横评使用的平台。考虑到处理器的主频及线程对于Quadro显卡会产生瓶颈,这里我们选择了双路的至强X5660系列,与之搭配的是惠普Z600工作站。
| 惠普Z600工作站 | |
| 处理器子系统 | |
|---|---|
| 处理器型号 | 双路Intel Xeon X5660 |
| 处理器架构 | Intel 32nm Westmere |
| 代号 | Westmere |
| 核心/线程数量 | 6/12 |
| 主频 | 2.8GHz |
| 处理器指令集 | MMX,SSE,SSE2,SSE3,SSSE3, SSE4.1,SSE4.2,EM64T,VT |
| 外部总线 | 2x QPI 3200MHz 6.40GT/s 单向12.8GB/s(每QPI) 双向25.6GB/s(每QPI) |
| L1 Code Cache | 6x 32KB 8路集合关联 |
| L1 Data Cache | 6x 32KB 4路集合关联 |
| L2 Cache | 6x 256KB 8路集合关联 |
| L3 Cache | 12MB 16路集合关联 |
| 主板 | |
| 主板型号 | HP |
| 芯片组 | Intel 5520 |
| 北桥芯片特性 | 2xQPI VT-d Gen 2 |
| 内存控制器 | 每CPU集成三通道R-ECC DDR3 1333 |
| 配置内存类型 | 4GB R-ECC DDR3 1333 SDRAM x2 |
| 图形子系统 | |
| 显卡型号 | NVIDIA Quadro |
| 核心代号 | Fermi |
| 显存容量 | 1GB RAM |
| 驱动程序 | NVIDIA Quadro 276.14 WHQL for Windows XP |
| 存储子系统 | |
| 磁盘控制器 | Intel ICH10R SATA AHCI Controller |
| 磁盘控制器规格 | 6x SAS 3Gb/s AHCI w/ NCQ RAID 0/1 |
| 磁盘控制器驱动 | Intel Matrix Storage Manager 8.8.0.1009 |
| 硬盘 | Seagate Barracuda 7200.12 ST3250318AS |
| 硬盘规格 | 7200RPM 250GB SATA 3Gb/s NCQ 16MB Cache |
| 网络连通性 | |
| 网卡 | Broadcom BCH5764MKMLG |
| 网卡驱动 | Broadcom博通NetXtreme II系列网卡驱动14.2.11.1 |
| 软件环境 | |
| 操作系统 | Microsoft Windows XP Professional x64 Edition SP2 |
和工作站测试不同,要想充分检测Quadro显卡的性能,我们最新的Windows 7系统虽然很先进,但是不能够支持SPEC软件。因此,这里我们只能选择之前主流的XP操作系统,当然这款操作系统在国内已然有着不少的受众。
作为Fermi系列的低端产品,Quadro 600显卡主要定位在入门级领域,是初级3D应用人士的好选择。






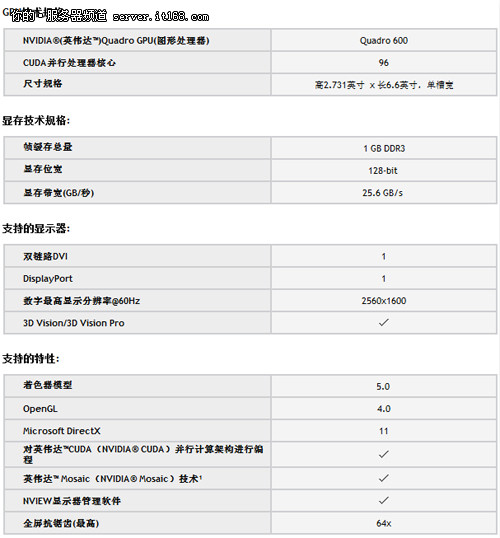
Quadro 600显卡规格介绍
Quadro 600显卡基于GF108核心,拥有96个流处理器,搭载GDDR3显存构成1GB/128bit规格,配备DisplayPort和DVI接口各一个,TDP为40W。在显存方面该款显卡由多颗DDR3显存组成1GB 128bit的显存规格,大容量的显存能够尽可能的满足系统运算的需求。丽台Quadro 600显卡配备DVI与DP接口,能够接驳专业显示器使用。
应该说,在最新的Fermi核心Quadro显卡中,Quadro 2000并非是最低端的一款,但却是最容易被大众接受的一款。我们知道,受限于Fermi架构的成本,新Quardo的售价都比较高,之前我们测试过的Quadro 5000超过了2万元人民币。而本次我们介绍的Quadro 2000价格却便宜得多,它目前的国内售价不足4000元,易于被专业人士所采用。



Fermi架构Quadro 2000显卡
Quadro 2000风扇拆解
显卡使用的GF106核心
显卡接口,提供了1个DVi和2个DP(同一时间,3个接口中只能有2个处于活动状态)
Quadro 2000显卡使用的显存颗粒
Quadro 2000显卡基于GF106核心,,有192个流处理器、128-bit 1GB GDDR5显存,核心/流处理器/显存频率625/1250/2600MHz,带宽41.6GB/s,输出接口有1个双链接DVI-I、2个DisplayPort,支持DX11、OpenGL 4.0、CUDA、3D Vision Pro、64x FSAA、SLI Multi-OS等技术,整卡最大功耗62W。





Quadro 4000
Quadro 4000显卡搭配了256个流处理器(CUDA核心),256-bit 2GB GDDR5显存,带宽89.6GB/s,一个双链接DVI-I和两个DisplayPort输出接口,支持64x FSAA全屏抗锯齿,最大功耗142W,单插槽散热器,尺寸9.50×4.376英寸(241.3×111.1厘米),支持双精度浮点运算。

Quadro 5000显卡
Quadro 5000显卡背面有巨大的散热片
使用独立的一个6PIN接口供电
SLI接口和SDI接口
显卡的外部接口,有1个DVI和2个DP接口
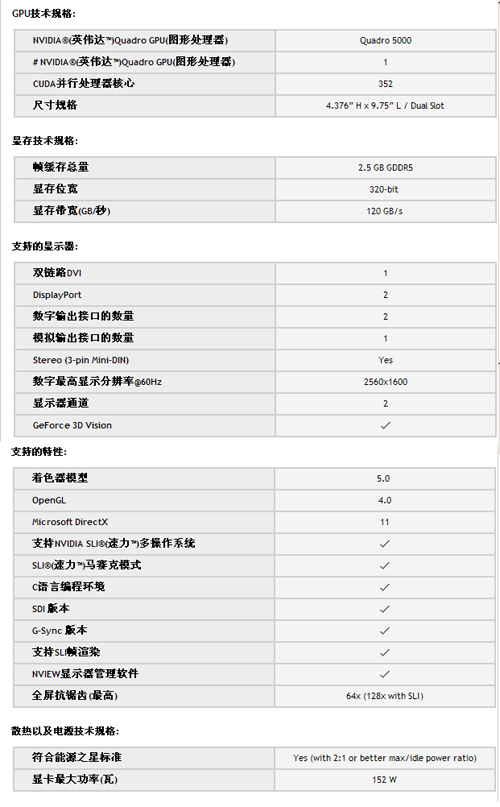
Quadro 5000显卡规格
Quadro 5000显卡的规格非常强大,提供了352个CUDA核心,显存容量达到了2560MB,显存位宽为320bit,显存带宽为120GB/s。对比上一代的FX5800来说,它的流处理器数量提升了160个,显存容量提升了1GB,显存带宽提升了43.2GB/s;唯一遗憾的是显存位宽略有下降。从这些数值来看,我们可以明显感觉到Quadro 5000在性能上会有比较大的提升,当然具体的提升幅度还是要测试之后才知道。
CineBench是基于Cinem4D工业三维设计软件引擎的测试软件,用来测试对象在进行三维设计时的性能,它可以同时测试处理器子系统、子系统以及显示子系统,我们的平台偏向于多一些,因此就只有前两个的成绩具有意义。和大多数工业设计软件一样,CineBench可以完善地支持多核/多处理器,它的显示子系统测试基于OpenGL。
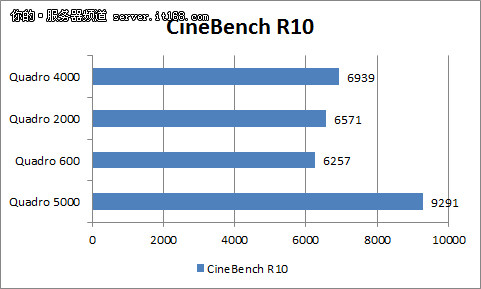
CineBench测试成绩分为两部分,这里我们只截取了显卡的部分。通过这个数据对比我们发现,虽然从高到低,显卡的成绩与定位成正比,但是除非是顶级的Quadro 5000,其他3款产品的差距并不大。换句话说,这不能反映出显卡的真实性能差距。R10这款软件太老了,在这次横评之后,我们在未来的测试中也将放弃它。
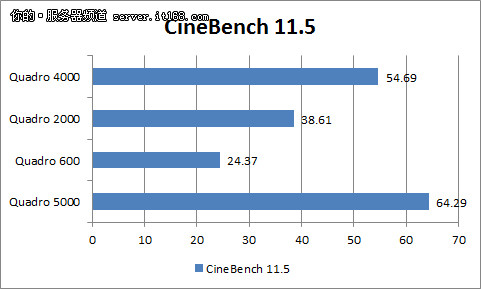
CineBench R11.5的计算方式与上一代的R10有着明显的不同,从这里可以看到了阶梯状的成绩区间,这个表现是与显卡的定位相符的,也是正常的。
SPECapc for 3ds Max 9是基于典型用户的使用情况设定的负载,在测试过程中会涉及到wireframe modeling、shading、texturing、lighting、blending、inverse kinematics、object creation and manipulation、editing、scene creation、particle tracing、animation 和 rendering。3ds Max 9提供了32位/64位两种版本,我们使用的是32位版本。
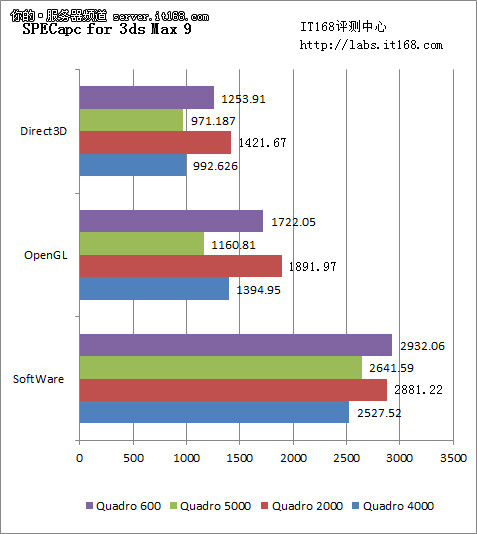
我们在3dsMax 9软件测试中,虽说Quadro 600是最低端的产品,但是从成绩来看它的表现并没有想象的那么差,也不像之前的测试那样长期处于垫底的位置。事实上,它在部分项目中的成绩甚至比Quadro 2000还强一些。Quadro 4000和5000虽然定位差距不小,但是实际的表现却没有那么大。最后说一句,这个成绩是越小越好的。
SPECViewperf 9.0是专业级、符合工业标准的 OpenGL 图形显示卡效能测试分析软件,其测试项目有六项:3dsmax、DRV、DX、Light、ProE、Ugs,包括软件执行效能仿真(3dsmax、ProE)、以及动画公园场景仿真(Light)。等等,可以产出相关的分析数据。
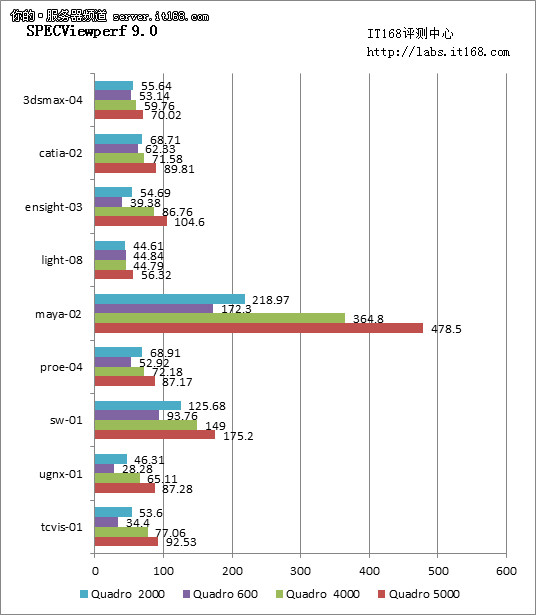
SPECViewperf 9软件测试中,许多项目中其实各个显卡的成绩差距并不大,唯一可以看得非常清楚的就算是Maya了。作为3D应用的主要平台之一,Maya平台承载了大量的应用,因此我们也结合这个数据进行分析。基本可以看出,从Quadro 600到Quadro 2000还是有提升的,只是并不大;而在Quadro 2000、Quadro 4000和Quadro 5000中,差距是非常明显的,正是这个项目让用户的钱花得物有所值。
既然刚刚提到了Maya,那么我们就来看看在Maya 2009上各款显卡的表现吧。

Autodesk Maya2009中有很多的改进,它可以帮助你更有生产力,包括Maya的Assets(资产),预选高亮(Pre-Selection highlighting),热图显示(Heat Map Display),属性传递(Transfer Attribute)以及强大用户界面更新。此外,您还可以发现Maya 2009中显著的性能改善,在许多领域,包括支持多线程的工作和算法,而且它相比之前版本的速度更快,加速模拟和渲染的表现,甚至可以支持更多巨大的场景。
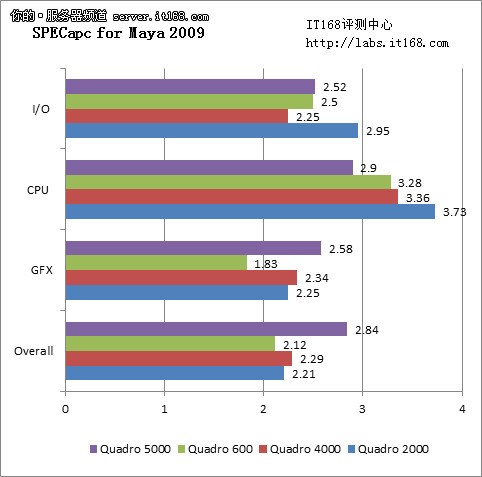
Maya 2009是CG应用中常见的基础平台,能否在此平台上流畅运行,也关系到CG制作的实际时间。从测试结果来看,除了Quadro 5000异军突起之外,其他3款显卡在这个项目中的表现并没有悬殊的差距,Quadro 4000和Quadro 600的实际表现只差不到10%。
去年6月底,SPEC组织旗下的图形性能测试项目组(SPECgpc)正式推出了Specviewperf 11工作站用专业图形综合测试软件,新版本的主要变化是采用了新的图形测试界面,以及增加了用于测试的新款专业级3D应用程度片段。SPECviewperf 11采用的新GUI图形界面令首次使用这款软件的新人也能很容易上手运行测试,读取测试成绩以及获取帮助信息等,此外,Windows和Linux操作系统下均使用同样的测试脚本,保证了不同平台下测试结果的可比性。

新版SPECviewperf 11中包含有8个不同的测试环节,每个环节都能模拟一款CAD/CAM软件,某些测试场景中甚至包含有超过6000万个顶点数据,能够充分测试出参测系统的整体性能与显卡的OpenGL性能。
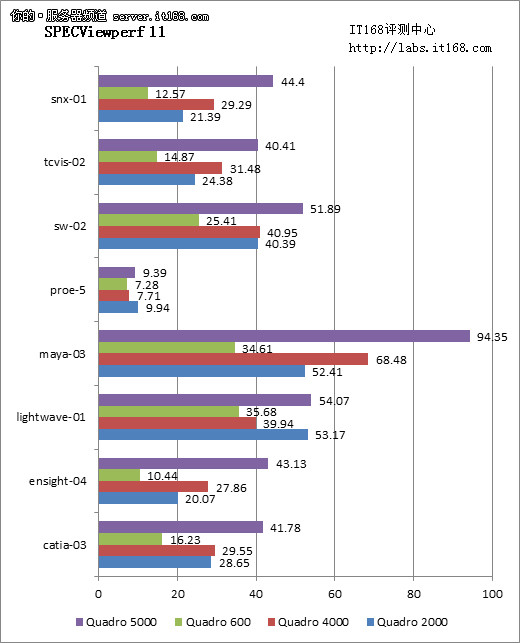
最后我们给出的是SPECviewperf 11测试成绩,测试的分辨率1920*1080。结合分辨率来说,越是低端的显卡越吃亏,因为更高的分辨率只能带来更差的性能表现。所以我们看到,Quadro 5000几乎囊括了所有的第一,这一点儿都不奇怪。就准确性来说,SPECviewperf 11是目前最新版本的专业卡测试软件,它的模型及特效应用都是最新的,也最能反映出显卡的实际表现。
横评总结:本次我们单独列举了4款Quadro Fermi架构的显卡进行评测,仅仅是希望通过对比让大家看到Quadro家族中显卡的性能差距。而从本次横评来看,并非高端的型号在应用中就一直保持优势,中低端的显卡在特殊的情况下也能提供不错的性能。由此,买显卡还得量力而行,只求最好,不求最贵,并非是上上策。


产品特点:彻底改变用户工作流程面貌 Quadro 5000专业图形解决方案基于创新的NVIDIA®(英伟达™)Fermi架构,最高可实现4倍于上一代产品的性能,能够满足各种设计、动画以及视频应用¹的需求。 Quadro 5000拥有全新的Scalable Geometry Engine™技术,每秒可处理惊人的9.5亿个三角形,树立了3D性能分数的全新标准²。 Quadro 5000集高性能计算与高级可视化于一身,可彻底改变现代工作流程的面貌。 革命性的Quadro Fermi架构 在运行光线追踪、视频处理以及计算流体..
产品详细信息>> - 暂无报道&评测 - 暂无驱动和公共程序 -