全国首发!AMD Shanghai/上海皓龙2378性能评测

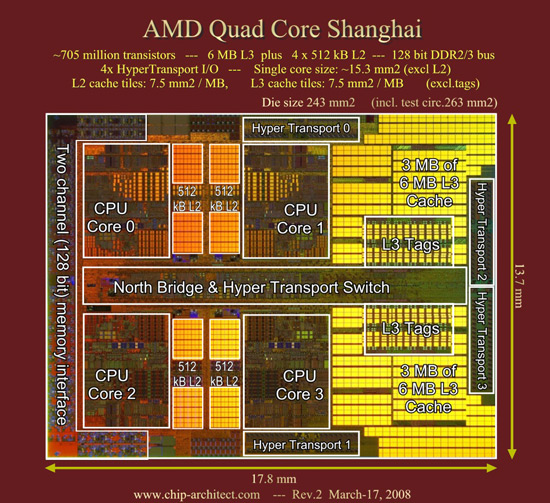
AMD 四核 Shanghai/上海架构图
AMD Shanghai/上海,采用了45nm工艺制程(这也是AMD CPU第一次采用45nm),集成了7.05亿晶体管,拥有共享6M的三级缓存,增强的双通道内存控制器可以同时支持DDR2内存和DDR3内存,内置了4条Hyper Transport总线以支持组建大规模并行系统,“上海”还支持AMD的快速虚拟化索引(RVI)的AMD-V虚拟化技术,同时具备48位物理寻址能力,寻址空间可以达到(256TB)。“上海”还兼容Socket F(1207),旧有的系统只需要升级BIOS就可以支持新的CPU,从而可以保护用户的投资。


AMD 45nm Shanghai/上海 Opteron 2378实物照
由于20天前,Shanghai就已经在国外发布了,因此在全球范围内已经有了一些零星的性能数据出现(例如一些国外的媒体上),然而完整的服务器性能评测尚未有见到,现在,我们IT168评测中心就带给你AMD Shanghai的实际性能表现。
作为AMD从65nm工艺转向45nm工艺的首款产品,AMD Shanghai在架构方面和上一代处理器Barcelona很相似,其实,处理器新架构的研发无不耗资甚巨,因此一个长生命力的架构对整个生态圈都是有利的,例如K8架构就一直沿用到现在,NetBurst架构也顽强地存活了近十年。如此这般,AMD Shanghai的架构也是在上一代产品上进行的改进,使用更先进的工艺制程,提高性能并提供新的功能。
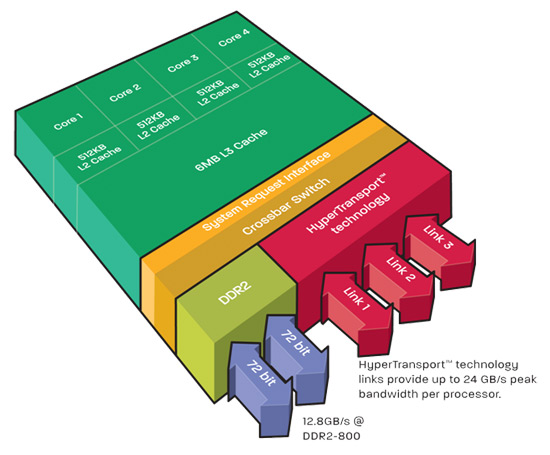
AMD Shanghai/上海架构图
仔细看,上海的架构(上)与巴塞罗那的架构(下),是不是很有相似之处?
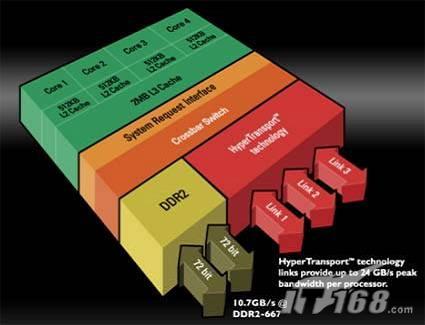
AMD Barcelona/巴塞罗那架构图
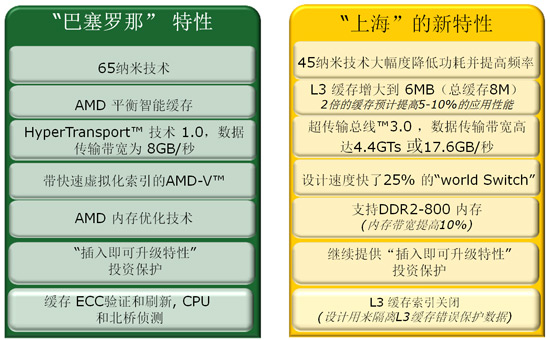
Shanghai的重点放在提升制程方面而不是架构方面,AMD Shanghai的指导思想就是让客户可以用很低的成本从Barcelona平滑过渡到Shanghai,为了保护用户的投资,Shanghai还采用了和Barcelona一样的Socket F 1207插槽。由于包括TLB问题在内的各种困扰,Barcelona一路坎坷,Shanghai的推出就是为了挽回市场,因此必须很平易近人。从现在的资料来看,Shanghai的确做到了这一点:良好的兼容性、更好的性能、更低的功耗以及更低的价格。
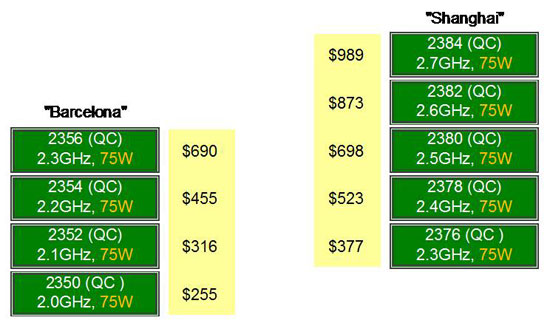
在同样的价格下,买到的Shanghai处理器的频率要比Barcelona要高,并且具有更强的性能

AMD 45nm Shanghai Opteron 2378实物照
概括起来,AMD上海的改进有:
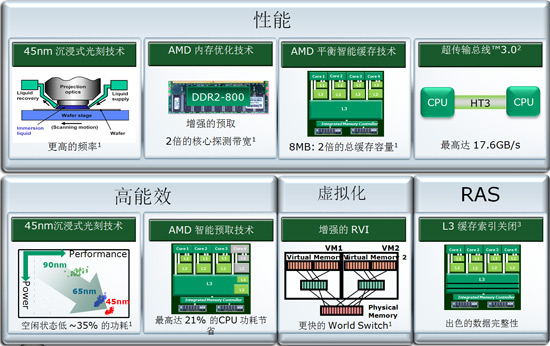
1、45nm沉浸式光刻技术,更低的功耗和更高的主频
2、更大的三级高速缓存,容量达到了6MB(上一代是2MB)
3、内存控制器的更新:支持DDR2-800, 比上一代DDR2-667的内存带宽提高10%。
4、AMD内存优化技术,增强的预取技术,2倍的核心探测带宽
5、支持HyperTransport 3.0总线,带宽增加到17.6GB/s(2.2GHz HT3,预计在2009年春)
6、增强的虚拟化技术:RVI,提升虚拟机切换速度并提供虚拟化迁移功能

AMD 45nm Shanghai Opteron 2378实物照

AMD Shanghai/上海晶圆超级大图(2560x1742),包括了4个完整的四核上海CPU

AMD Shanghai核心区间划分,注意和上图CPU核心的方向刚好是左右相反的

AMD Shanghai/上海晶圆,注意和上图相比,L3缓存的面积有所降低
AMD的45纳米制程工艺是联合IBM一同研发的。有趣的是,与英特尔的高-K金属栅极不同,AMD和IBM的技术是超低K电介质互联。而另两项相关技术分别是:多重增强晶体管应变技术和沉浸式平板印刷术。
简单来说,多空、超低K电介质可以降低串联电容、降低写入延迟和能量消耗,从而明显提升性能功耗比;而沉浸式平板印刷术,实际上就是在激光蚀刻头的中间加入一种特殊的液体来修正光的折射,从而让其在晶圆上更好的刻录晶体管。用这种工艺设计生产的SRAM芯片可获得大约15%的性能提升。真正解决AMD在45纳米技术难题的是多重增强晶体管应变技术,AMD和IBM称,与非应变技术相比,这一新技术能将P沟道晶体管的驱动电流提高80%,将N沟道晶体管的驱动电流提高24%。
AMD表示,这些技术不但可以用在45纳米领域,还是未来32纳米处理器制程的关键技术。

左:45nm Shanghai Opteron 2378
右:65nm Barcelona Opteron 2354

左:45nm Shanghai Opteron 2378
右:65nm Barcelona Opteron 2354

左:45nm Shanghai Opteron 2378
右:65nm Barcelona Opteron 2354

架构图:Intel Nehalem VS AMD Shanghai
|
AMD Shanghai VS AMD Barcelona VS Intel Nehalem | |||||
|
|
AMD Shanghai | AMD Barcelona | Intel Nehalem | ||
|
工艺 |
45nm |
65nm |
45nm | ||
| 晶体管数量 | 7.05亿 | 4.63亿 | 7.31亿 | ||
| 核心数量 | 4核 | 4核 | 4核 | ||
|
核心尺寸(宽x高) |
13.7mm x 17.8mm | - | 13.0mm x 18.9mm | ||
|
核心面积 |
243mm2 |
283mm2 |
246mm2 | ||
|
每核心面积(不包括L2) |
~15.3mm2 | - | ~24.4mm2 | ||
|
L2缓存 |
4 x 512KB |
4 x 512 KB | 4 x 256 KB | ||
|
L2缓存面积 |
4? x 3.75mm2 |
- |
4 x 1.78mm2 | ||
|
L3缓存 |
6MB | 2MB | 8MB | ||
|
L3缓存面积(不包括Tag) |
45mm2 | - | 45.6mm2 | ||
|
内存控制器 |
双通道DDR2 533/667/800 双通道DDR3 |
双通道DDR2 533/667 | 三通道DDR3 | ||
|
IO总线 |
3 x HT1.0 双向带宽8GB/s 未来会支持4x HT3.0 双向带宽17.6GB/s |
3 x HT1.0 双向带宽8GB/s 未来会支持更多数量 |
2 x QPI | ||
桌面版本的Nehalem处理器评测,我们已经有了不少的文章:再攀性能之巅 Intel全新酷睿i7深度评测、性能大幅提升 Core i7 服务器应用测试。
一直以来,AMD平台在芯片组上面可以说是处于劣势,竞争对手Intel推行的平台策略,每当新的处理器推出的时候,总有成套的芯片组、主板推出,并不断地改进、优化,而AMD这方面一直依赖于第三方芯片组提供商(AMD自家也有服务器芯片组,不过很是少见)。

Tyan S2932-E双路Opteron主板,也是今次测试使用的主板
很微妙地,在服务器市场,其芯片组都依赖于AMD在图形市场的竞争对手??NVIDIA的芯片组(还有ServerWorks也有相关芯片组产品;ServerWorks已被Broadcom收购)。虽然Opteron处理器已经集成了内存控制器,不过外部IO对于服务器来说是至关重要的,因此第三方芯片组主要扮演的是PCIE/PCI-X总线提供者,用来连接各种外部设备。比AMD Shanghai早些时候发布的Intel Nehalem架构里面采用的模块化设计已经可以将PCIE控制器、显卡等集成在处理器内部,这方面Intel的设计可以说是走在了AMD的前方??相对于直联架构、集成内存控制器这方面落后来说。
然而Shanghai核心的服务器产品已经现身市场了,而Nehalem服务器版本仍然要等到2009年度,因此AMD仍然具有时间来进行同样的工作。
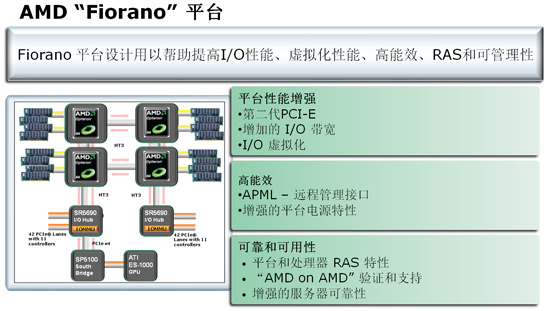
AMD支持四路Shanghai处理器的Fiorano平台,基于SR5690 IOH和SP6100南桥
不管如何,在近几年内,AMD仍然需要使用芯片组,虽然目前存在的nForece Pro平台之需要进行一些Microcode升级就可以支持上海处理器,然而总是依赖于第三方芯片组也不现实,因此AMD将会在明年推行一个叫做Fiorano的平台解决方案,由SR5690 I/O Hub和SP6100南桥组成,每个SR5690通过HT3.0总线连接到一个Shanghai处理器,提供42条PCIE Lanes,并集成了IOMMU来提供I/O虚拟化功能。Fiorano平台包括了两个SR5690芯片,因此可以提供强大的I/O带宽。其实只要AMD愿意,它甚至可以每一个Shanghai Opteron配备一个SR5690芯片。
Fiorano平台也不一定是4路的,最有可能也应该是最普及的应该是双路Shanghai服务器/工作站,在工作站配置下,可以配置两块SR5690芯片,总共提供4条PCIE x16插槽,图形工作站应该会采用这种配置。
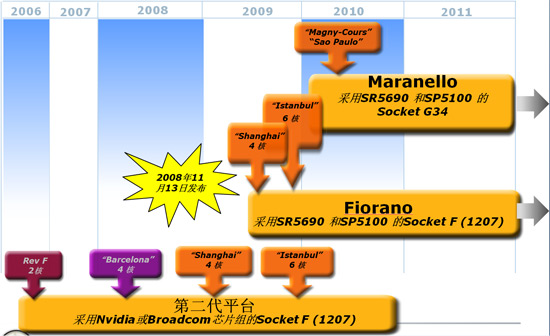
早在07年底AMD推Barcelona的时候,其路线图上就已经出现了Shanghai的身影,现在,路线图上Shanghai的下一代自然也就浮出水面了,它就是Magny-Cours马尼库尔、Sao Paulo圣保罗。在它们之间,将会有一款6核心的Shanghai处理器产品,名字就叫Istanbul伊斯坦布尔。和Barcelona巴塞罗那、Shanghai上海都是地名一样,Magny-Cours马尼库尔在法国、Sao Paulo圣保罗则在巴西,而Istanbul伊斯坦布尔是位于土耳其(全称:土耳其共和国The Republic of Turkey)的一个海港。
预计明年推出的Istanbul将会采用6核心设计
Istanbul同样也采用了45nm制程工艺,并且也会同样是基于Shanghai核心,提升核心数量是提升计算密度的一个常用、有效的方法。Istanbul将会实现当前Shanghai未能实现的HT3.0总线。当然现在的Shanghai处理器未能实现HT3.0也是因为芯片组的缘故,预计Istanbul面市的时候,AMD Fiorano平台已经准备好了。更大的连接带宽可以提升处理器之间的连接速率和处理器与IOH之间的连接速率,进一步提升处理器的性能。明年Q2的上海将可以提供HT3.0。

AMD六核心Istanbul伊斯坦布尔架构图
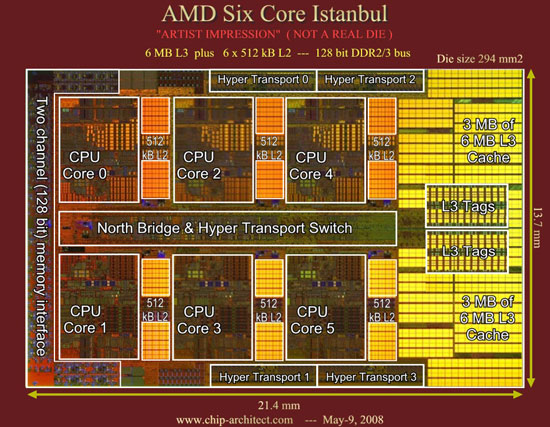
AMD六核心Istanbul伊斯坦布尔架构猜想图
Intel也于前段时间推出了六核心的45nm Penryn产品,而Nehalem-EP也会具有6核心乃至8核心的版本。
基于AMD保护用户投资的思想,现有的Opteron平台可以很容易地升级到Shanghai平台,当然,现在要使用Shanghai处理器,你也没有其他选择,Fiorano平台还没有出来。本次Shanghai评测基于一台曙光A650服务器,原配的是双路Barcelona Opteron 2350处理器,测试结果并会与我们IT168评测中心的DELL PowerEdge 2900 III服务器进行对比,测试对比平台的详细参数如下:
|
测试平台、测试环境 | |||||
|
测试分组 | |||||
|
处理器子系统 | |||||
|
处理器 |
双路AMD Shanghai Opteron 2378 |
双路AMD Barcelona Opteron 2350 |
双路Intel Xeon E5430 | ||
|
处理器架构 |
AMD 45nm Shanghai | AMD 65nm Barcelona | Intel 45nm Penryn | ||
|
处理器代号 |
Shanghai | Barcelona | Harpertown | ||
|
处理器封装 |
Socket F 1207 | Socket F 1207 | Socke 771 LGA | ||
|
处理器规格 |
四核 | 四核 | 四核 | ||
|
处理器指令集 |
MMX,3DNow!,SSE,SSE2,SSE3,SSE4A,x86-64 | MMX,3DNow!,SSE,SSE2,SSE3,SSE4A,x86-64 | MMX,SSE,SSE2,SSE3,SSSE3, SSE4.1,EM64T,VT | ||
| 主频 | 2.40GHz | 2.00GHz | 2.66GHz | ||
| 处理器外部总线 | HTL:1000MHz | HTL:1000MHz |
FSB:1333MHz | ||
|
L1 D-Cache |
4x 64KB 2路集合关联 |
4x 64KB 2路集合关联 |
4x 32KB 8路集合关联 | ||
|
L1 I-Cache |
4x 64KB 2路集合关联 |
4x 64KB 2路集合关联 |
4x 32KB 8路集合关联 | ||
|
L2 Cache |
2x 512KB 16路集合关联 |
2x 512KB 16路集合关联 |
2x 6144KB 16路集合关联 | ||
|
L3 Cache |
6MB 48路集合关联 |
2MB 32路集合关联 |
|||
|
主板 | |||||
|
主板型号 |
Tyan S2932-E |
Tyan S2932-E |
DELL PE2900 III | ||
|
北桥芯片组(MCH) |
NVIDIA nForce PRO 3600 | NVIDIA nForce PRO 3600 | Intel 5000X | ||
| 北桥芯片特性 | - | - | 12MB Snoop Filter | ||
|
内存控制器 |
每CPU集成双通道DDR2-800 | 每CPU集成双通道DDR2-667 | 北桥集成四通道FBD DDR2 | ||
|
内存 |
2GB R-ECC DDR2 667 SDRAM x4 | 2GB R-ECC DDR2 667 SDRAM x4 | 2GB FBD DDR2 667 SDRAM x4 | ||
|
系统磁盘子系统 | |||||
|
磁盘控制器 |
LSI MegaRAID SAS Controller |
LSI MegaRAID SAS 8208ELP Controller |
DELL Perc 5/i RAID Controller | ||
|
磁盘控制器规格 |
SAS 3Gbps | SAS 3Gbps | SAS 3Gbps | ||
|
磁盘控制器设置 |
RAID 5 |
RAID 5 |
RAID 5 | ||
|
磁盘控制器驱动 |
LSI MegaRAID SAS 3.8.0.32 |
LSI MegaRAID SAS 3.8.0.32 |
LSI SAS 3.8.0.32 | ||
| 磁盘 |
Fujitsu MBA3147RC x3 |
Fujitsu MBA3147RC x3 |
Seagate Cheetah 15K.5 ST314655SS x3 | ||
|
磁盘规格 |
15000RPM 147GB SAS 3Gbps 16MB Cache |
15000RPM 147GB SAS 3Gbps 16MB Cache |
15000RPM 146GB SAS 3Gbps 16MB Cache | ||
|
磁盘设置 |
SATA 3Gbps 30GB系统分区 |
SATA 3Gbps 30GB系统分区 |
SAS 3Gbps 20GB系统分区 | ||
|
网络子系统 | |||||
|
网卡 |
NVIDIA nForce Pro 3600 integrated MAC with Marvell 88E1121 PHY GbE Controller x2 | NVIDIA nForce Pro 3600 integrated MAC with Marvell 88E1121 PHY GbE Controller x2 | Broadcom BCM5708C PCI-E千兆网卡 x2 | ||
|
网卡设置 |
ForceWare Teaming Load Balancing |
ForceWare Teaming Load Balancing |
Broadcom NIC Teaming Load Balancing | ||
|
网卡驱动 |
NVIDIA NIC/LAN v67.76.1 | NVIDIA NIC/LAN v67.76.1 | Broadcom NetXtreme 2 11.04.01 | ||
|
软件环境 | |||||
| 操作系统 |
Microsoft Windows Server 2003 R2 Enterprise Edition SP2 |
Microsoft Windows Server 2003 R2 Enterprise Edition SP2 |
Microsoft Windows Server 2003 R2 Enterprise Edition SP2 | ||
三个平台都同样为流行的双路四核配置,磁盘子系统也相仿,都是基于LSI的硬件阵列卡,三个15000RPM SAS硬盘组建RAID 5阵列。在测试的时候均使用了端口聚合功能来提升网络IO带宽。
需要特别注明的一点是:Shanghai处理器支持R-ECC DDR2-800内存,而曙光A650服务器搭配的只是R-ECC DDR2-667内存,性能上会有所差异。尚不清楚Tyan S2932-E能否使用R-ECC DDR2-800内存。
最后,还有两点不得不特别说明:首先,我们的基准平台基于Intel 5000X芯片组,带有12MB Snoop Filter缓存,它可以提升在内存密集型计算方面的效率,比起主流的Intel 5000P芯片组具有比较明显的优势。
其次,曙光服务器的主板采用了NVIDIA nForce Pro 3600芯片组自带的网络控制器(Mac控制器 + Marvell 88E1121 PHY芯片),它的网卡Teaming功能非常不同凡响:

NVIDIA的网卡组合技术??也就是一般所说的网卡Teaming功能
这个功能有时会因为提示网卡使用了VLAN而无法打开(当然这时候VLAN功能是已经关闭了),并且几经周折设置好了之后,它和通常的网卡Teaming表现不同:它居然没有增加新的虚拟聚合网卡!例如Intel、Marvell、Broadcom这样的网卡厂商,在使用端口聚合/Teaming功能之后,都会生成一个新的虚拟网卡,这个网卡就是可以设置IP地址等信息的管理所有流量的网卡。
这两块NVIDIA的网卡不是这样,在设置网卡组合功能之后,系统设备完全没有变化??你需要在一块网卡上设置好IP地址、网关、子网掩码,同时保留另外一块网卡为自动获取IP,这样才能正常使用组合功能。希望用到这个功能的新用户看了之后可以不用再走我们走过的弯路。
测试方法介绍
-
ScienceMark v2.0 Membench
ScienceMark v2.0是一款用于测试系统特别是处理器在科学计算应用中的性能的软件,MemBenchmark是其中针对处理器缓存、系统内存而设计的功能模块,它可以测试系统内存带宽、L1 Cache延迟、L2 Cache延迟和系统内存延迟,另外还可以测试不同指令集的性能差异。
-
CineBench R10
CineBench是基于Cinem3D物理建模软件的一个测试程序,主要针对处理器子系统、内存子系统和显示子系统,可以完善地支持多核/多线程。对于服务器来说显示子系统并不重要,因此主要用它来测试处理器子系统和内存子系统。
-
SiSoftware Sra 2009
SiSoftware Sra是一款可运行在32bit和64bit Windows操作系统上的分析软件,这款软件可以对于系统进行方便、快捷的基准测试,还可以用于查看系统的软件、硬件等信息。我们使用了SiSoftware Sra的2009版,它可以支持各种最新的CPU指令集,并能良好地支持多核、多线程,我们主要用其来评估平台的理论计算性能。
-
WebBench v5.0
WebBench是针对服务器作为Web Server时的性能进行测试,我们在被测服务器上安装了IIS6.0组件,以提供测试所需的Web服务。在测试中我们开启了网络实验室中的56台客户端,分别使用了WebBench 5.0内置的动态CGI以及静态页面脚本对服务器进行了测试。
静态测试是由客户端读取预先放置在服务器Web Server下的Web页面(wbtree),这项测试主要考察的是服务器磁盘系统以及网络连接性能。我们使用了实验室中的56台客户端,配合Static_mt.tst多线程静态脚本测试向被测服务器发送请求。
动态测试偏重于对服务器CPU子系统的性能测试,它对于Web服务器提供了足够的负载。我们将一个C语言编写的CGI源文件Simcigi.c编译为Simcgi.exe,并将其作为动态测试中的CGI脚本。在测试过程中,每台安装了WebBench客户端软件的PC,会在300秒的时间内持续向服务器发送CGI请求,而控制台会纪录并汇总服务器所响应CGI请求的数据。CGI测试的成绩高低,主要取决于服务器处理器子系统性能的优劣。处理器子系统包括CPU、内存以及内存控制器,CPU频率、缓存以及内存容量大小和内存带宽,都会影响该项成绩。
-
NetBench v7.03
NetBench是针对文件服务器的性能测试软件,影响NetBench性能的主要是服务器的磁盘子系统,服务器磁盘控制器、条带大小、读写缓存、硬盘类型、组建磁盘阵列模式、内存容量、网络拓朴结构等都会对测试结果有明显的影响。我们在被测服务器上设立了文件服务器,NetBench通过网络实验室中60个客户端来模拟网络中的PC向文件服务器所发出的文件传输请求,文件服务器则将存储在磁盘上的文件数据发送给相应的客户端。在测试过程中,客户端会以每四台一组的步进依次增加并且向服务器发送文件传输请求,测试结束后控制台收集数据并绘制出服务器的数据传输变化曲线。
-
Benchmark Factory 4.6
大部分的服务器应用都同数据库有着密切的联系,因此在服务器测试当中这是一个很重要的测试。我们选择了Benchmark Factory 4.6软件和Microsoft SQL Server 2005来测试不同的硬件平台在数据库应用中的表现。
我们选择了BF内置的标准测试脚本AS3AP,这项测试可用于对于ANSI结构化查询语言(SQL)关系型数据库进行测试,它可用于测试DBMS(单用户微机数据库管理系统),也可用于测试高性能并行或者分布式数据库。

左:45nm Shanghai Opteron 2378
右:65nm Barcelona Opteron 2354
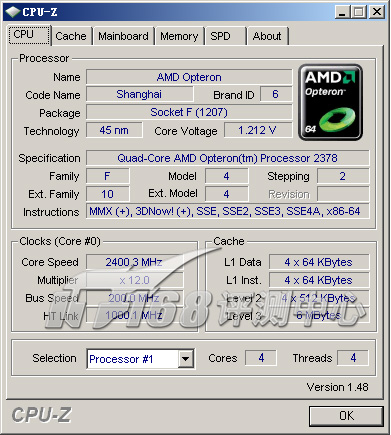
AMD Shanghai Opteron 2378处理器,主频2.4GHz。HT总线频率1GHz
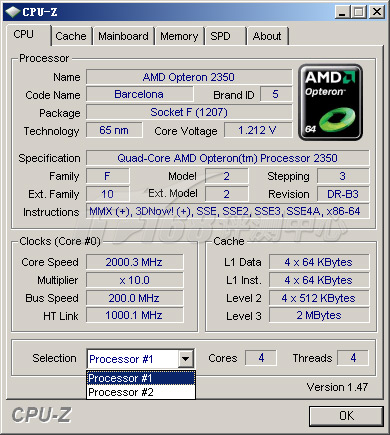
AMD 65nm Barcelona Opteron 2350处理器,主频2.0GHz。HT总线频率1GHz

Intel 45nm Harpertown Xeon E5430处理器,主频2.66GHz。FSB传输频率1333MHz
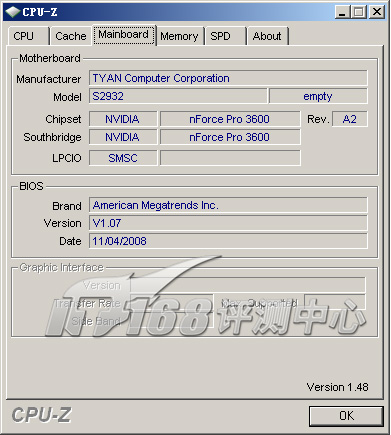
我们使用的曙光服务器的主板实际上就是Tyan S2932-E主板,基于nForece Pro 3600芯片组
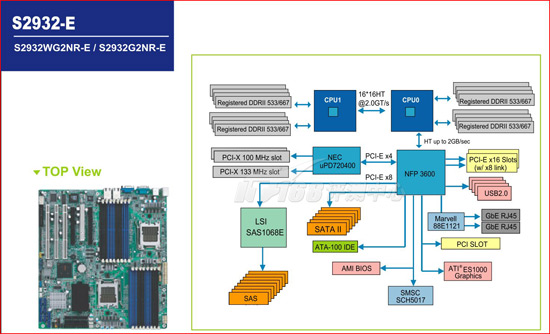
Tyan S2932-E双路Opteron主板
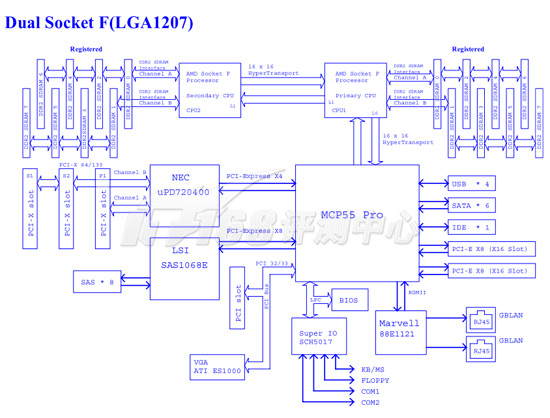
Tyan S2932-E主板逻辑架构图
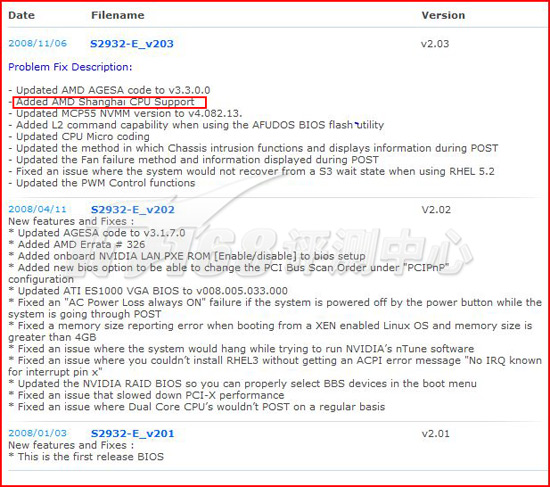
使用最新的BIOS以支持Shanghai处理器
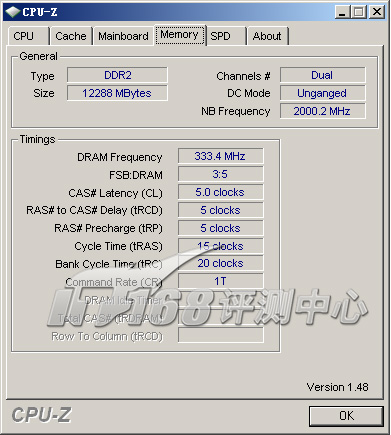
Unganged双通道模式,Unganged就是未分组的意思,这种模式下两个内存通道独立工作。测试表明各方面性能和Ganged模式没有什么分别
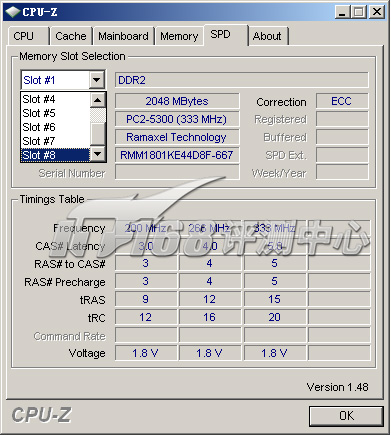
8GB R-ECC DDR2 667 SDRAM
SiSoftware Sra Pro Business 2009
SiSoftware Sra是一款可运行在32bit和64bit Windows操作系统上的分析软件,这款软件可以对于系统进行方便、快捷的基准测试,还可以用于查看系统的软件、硬件等信息。从Sra 2007开始支持SSE4指令集。SiSoftware Sra所有的基准测试都针对SMP和SMT进行了优化,最高可支持32/64路平台,这也是我们选择这款软件的原因之一。
|
SiSoftware Sra Pro Business 2009 | |||
|
测试对象 |
Dawning A650 双路AMD Shanghai Opteron 2378 2.4GHz |
Dawning A650 双路AMD Barcelona Opteron 2350 2.0GHz |
DELL PE2900 III 双路Intel Harptown Xeon E5430 2.66GHz |
|
Processor Arithmetic Benchmark 处理器架构测试 | |||
| Dhrystone ALU |
63082MIPS |
51480MIPS |
91006MIPS |
| Dhrystone ALU vs SPEED | 26.28MIPS/MHz | 25.74MIPS/MHz | 34.21MIPS/MHz |
|
Whetstone iSSE3 |
62993MFLOPS |
51400MFLOPS |
78385MFLOPS |
| Dhrystone iSSE3 vs SPEED | 26.25MFLOPS/MHz | 25.70MFLOPS/MHz | 29.47MFLOPS/MHz |
|
Processor Multi-Media Benchmark 处理器多媒体测试 | |||
|
Multi-Media Int x8 aSSE2 |
187.70MPixel/s |
155.64MPixel/s |
|
| Multi-Media Int x8 iSSE4.1 | 199.33MPixel/s | ||
|
Multi-Media Int x8 aSSE2 vs SPEED |
78.21kPixels/s/MHz | 77.82kPixels/s/MHz | |
| Multi-Media Int x8 iSSE4.1 vs SPEED | 74.94kPixels/s/MHz | ||
|
Multi-Media Float x4 iSSE2 |
81.53MPixel/s |
67.86MPixel/s |
108.69MPixel/s |
|
Multi-Media Float x4 iSSE2 vs SPEED |
33.97kPixels/s/MHz | 33.93kPixels/s/MHz | 40.86kPixels/s/MHz |
|
Multi-Media Double x2 iSSE2 |
44.51MPixel/s |
37.15MPixel/s |
55.75MPixel/s |
|
Multi-Media Double x2 iSSE2 vs SPEED |
18.55kPixels/s/MHz | 18.58kPixels/s/MHz | 20.96kPixels/s/MHz |
|
Multi-Core Efficiency Benchmark | |||
|
Inter-Core Bwidth |
6.54GB/s |
2.91GB/s |
20.54GB/s |
|
Inter-Core Bwidth vs SPEED |
2.79MB/s/MHz | 1.49MB/s/MHz | 7.91MB/s/MHz |
|
Inter-Core Latency (越小越好) |
128ns |
185ns |
90ns |
|
Inter-Core Latency? vs SPEED (越小越好) |
0.05ns/MHz | 0.09ns/MHz | 0.03ns/MHz |
|
Memory Bwidth Benchmark 内存带宽测试 | |||
|
Int Buffd iSSE2 Memory Bwidth |
16.59GB/s |
7.12GB/s |
6.13GB/s |
|
Int Buffd iSSE2 Memory Bwidth vs SPEED |
25.52MB/s/MHz | 10.94MB/s/MHz | 9.43MB/s/MHz |
|
Float Buffd iSSE2 Memory Bwidth |
16.58GB/s |
7.13GB/s |
6.13GB/s |
|
Float Buffd iSSE2 Memory Bwidth vs SPEED |
25.50MB/s/MHz | 10.96MB/s/MHz | 9.43MB/s/MHz |
|
Memory Latency Benchmark 内存延迟测试 | |||
|
Memory(Rom Access) Latency (越小越好) |
106ns |
157ns | 108ns |
|
Memory(Rom Access) Latency vs SPEED (越小越好) |
0.16ns/MHz | 0.24ns/MHz | 0.16ns/MHz |
|
Speed Factor (越小越好) |
83.80 |
103.40 | 95.20 |
|
Internal Data Cache |
3clocks |
3clocks | 3clocks |
|
L2 On-board Cache |
16clocks |
16clocks | 18clocks |
|
L3 On-board Cache |
58clocks |
47clocks |
|
|
Cache Memory Benchmark 缓存及内存测试 | |||
|
Cache/Memory Bwidth |
77.08GB/s |
51.17GB/s |
68.88GB/s |
|
Cache/Memory Bwidth vs SPEED |
32.89MB/s/MHz | 26.20MB/s/MHz | 26.52MB/s/MHz |
|
Speed Factor |
36.00 |
45.50 |
111.90 |
| Internal Data Cache | 299GB/s | 244.31GB/s | 421.23GB/s |
| L2 On-board Cache | 162.91GB/s | 135.04GB/s | 122.68GB/s |
|
.NET Arithmetic Benchmark .NET架构测试 | |||
|
Dhrystone .NET |
12736MIPS |
9551MIPS |
10562MIPS |
|
Dhrystone .NET vs SPEED |
5.31MIPS/MHz | 4.78MIPS/MHz | 3.97MIPS/MHz |
|
Whetstone .NET |
38737MFLOPS |
31231MFLOPS |
45399MFLOPS |
|
Whetstone .NET vs SPEED |
16.14MFLOPS/MHz | 15.62MFLOPS/MHz | 17.07MFLOPS/MHz |
|
.NET Multi-Media Benchmark .NET多媒体测试 | |||
|
Multi-Media Int x1 .NET |
24.48MPixel/s |
20.11MPixel/s |
31.28MPixel/s |
|
Multi-Media Int x1 .NET vs SPEED |
10.20kPixels/s/MHz | 10.06kPixels/s/MHz | 11.76kPixels/s/MHz |
|
Multi-Media Float x1 .NET |
5.29MPixel/s |
4.34MPixel/s |
8.68MPixel/s |
|
Multi-Media Float x1 .NET vs SPEED |
2.20kPixels/s/MHz | 2.17kPixels/s/MHz | 3.26kPixels/s/MHz |
|
Multi-Media Double x1 .NET |
21.31MPixel/s |
17.49MPixel/s |
24.75MPixel/s |
|
Multi-Media Double x1 .NET vs SPEED |
8.88kPixels/s/MHz | 8.74kPixels/s/MHz | 9.30kPixels/s/MHz |
SiSoftware Sra对比,用蓝色标出了性能特出的项目
和老的巴塞罗那相比,Multi-Core Efficiency Benchmark、Memory Bwidth Benchmark、Memory Latency Benchmark、Cache Memory Benchmark的成绩都得到了明显的提升,而且是在除以处理器主频的情况下,这表明处理器核心之间的Crossbar设计以及内存控制器的效率都得到了很大的改进,性能得到了成倍以上的提升。
不过,我们注意到Shanghai L3缓存的延迟似乎要比Barcelona的要高一些,此外,在纯粹的整数/浮点运算性能还具有5%左右的提升。另外,SiSoftware Sra通常看起来会偏向Intel处理器一些,因为它可以很好地支持Intel的SSE4指令集,而AMD Shanghai的SSE4A等指令集就没这么好运了,这也能表现出Intel在编译器方面做出的努力。
详细的处理器运算效能,请期待我们的SPEC CPU 2006测试。这个测试要运行数天之久,调试也比较麻烦,因此本文未能包及。
ScienceMark v2.0 Membench
ScienceMark v2.0是一款用于测试系统特别是处理器在科学计算应用中的性能的软件,MemBenchmark是其中针对处理器缓存、系统内存而设计的功能模块,它可以测试系统内存带宽、L1 Cache延迟、L2 Cache延迟和系统内存延迟,另外还可以测试不同指令集的性能差异。

ScienceMark v2.0 Membench L1测试成绩

ScienceMark v2.0 Membench L2测试成绩
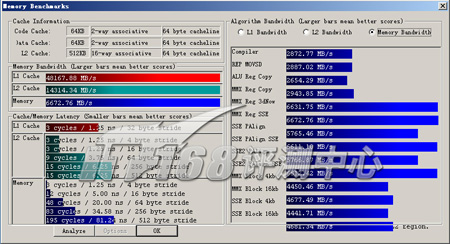
ScienceMark v2.0 Membench 内存测试成绩
首先我们进行的是ScienceMark的测试,主要考察系统的缓存和内存子系统情况。L1/L2 Cache的成绩主要是跟处理器频率相关,因为目前的处理器当中L1 Cache都是和处理器核心同频率的,而L2 Cache基本上也是??当前的处理器L2都是全速的(放置在处理器内但不在同一个芯片上的Pentium II为半速L2,而Pent