超越图形界限 AMD并行计算技术全面解析(二)

正睿科技 发布时间:2010-08-25 16:28:43 浏览数:18453
NVIDIA在最近3年中更新了3次GPU硬件架构,它们分别是:
● 面向DirectX 10游戏设计以G80G92为主的第一代统一渲染架构
● 面向游戏和通用计算并重的GT200架构(不包含GT210 220 240)
● 面向大规模并行计算和游戏并重的Fermi GF100架构
● 面向DirectX 10游戏设计以G80G92为主的第一代统一渲染架构
● 面向游戏和通用计算并重的GT200架构(不包含GT210 220 240)
● 面向大规模并行计算和游戏并重的Fermi GF100架构
而ATI在最近3年中,成功推出了4款GPU硬件架构,它们分别是:
● HD2000系列第一代统一渲染架构
● HD3000系列平衡和改进型统一渲染架构
● HD4000系列扩张型优化后端和增添LDS缓冲架构
● HD5000系列支持DirectX 11放大版优化通用计算统一渲染架构
● HD2000系列第一代统一渲染架构
● HD3000系列平衡和改进型统一渲染架构
● HD4000系列扩张型优化后端和增添LDS缓冲架构
● HD5000系列支持DirectX 11放大版优化通用计算统一渲染架构
几乎在每一代架构更替中,AMD都能通过其强大的细分市场能力制造出数量庞大而又密集的GPU产品线,NVIDIA的产品线则相对于单一,特别是在1000元以下市场很容易被对手包围。
AMD强大的细分市场能力已经无数次得到市场验证,特别是HD5000系列产品中,在确认了HD5870的优势之后,AMD不断细化市场,诞生了以下几个定位卓越市场控制力优秀的产品:

AMD密集的产品线规划
● HD5970 单卡双芯设计,代表了目前单卡GPU顶级性能;
● HD5870 最强单卡单芯设计,在功耗和发热可控的情况下提供优秀的3D性能
● HD5830 高性能级别GPU产品,流处理器数量精简到1120个,让用户可以用更低的价格买到高端GPU;
● HD5770 拥有和GTX260+相仿的性能,但是999元的售价非常切合主流用户的消费心理;
● HD5670 超越NVIDIA的GT240,和9800GT平起平坐,价格上具有一定优势;
● HD5550 在500价位上提供了DirectX 11、Eyefinity和Stream等技术支持,320个流处理器让它压制了对手GT220的进攻,超低价格和新技术是主要卖点。
● HD5870 最强单卡单芯设计,在功耗和发热可控的情况下提供优秀的3D性能
● HD5830 高性能级别GPU产品,流处理器数量精简到1120个,让用户可以用更低的价格买到高端GPU;
● HD5770 拥有和GTX260+相仿的性能,但是999元的售价非常切合主流用户的消费心理;
● HD5670 超越NVIDIA的GT240,和9800GT平起平坐,价格上具有一定优势;
● HD5550 在500价位上提供了DirectX 11、Eyefinity和Stream等技术支持,320个流处理器让它压制了对手GT220的进攻,超低价格和新技术是主要卖点。
产品:ATI Radeon HD 4850 显示芯片 
未来ATI图形芯片架构预测
● 未来ATI图形芯片架构预测
我们根据各方面的情报综合考虑,下一代即将到来的“Southern Isl”(“南岛”)还是延续R600架构,但是把曲面细分单元(Tessellator)放在VLIW Core中,这是一次非常难得的改进。但同时这也是南岛的极限。因为要把固定功能单元要挂到VLIW Core中,就要有独立的总线连接、独立的资源、寄存器、端口,也就是说独立的线程仲裁分配能力。
在VLIW Core中实现独立仲裁分配能力,是AMD一直希望在GPU中做到的,如果能做到这一点,那AMD或许能够借此实现更深级别的乱序执行,这基本上就和NVIDIA站在同一起跑线。同时如果把曲面细分单元(Tessellator)放在VLIW Core中,曲面细分能力将伴随芯片规模而变化,高中低端显卡将拥有各自不同的曲面细分能力。这和NVIDIA将曲面细分单元(Tessellator)放在SM中是一个道理。

AMD下代“南岛”架构两种设计方向推测
如果南岛无法一次性将曲面细分单元(Tessellator)放在VLIW Core中,可以选择另外一种途径,那就是对GPU内部单元进行分频。正如NVIDIA将CUDA Cores的频率以两倍于固定单元频率运行一样,AMD可以选择将几何性能较弱的Setup Engine和Tessellator等单元按一定幅度提升频率。
或者将GPU的前端超线程发送器(Ultra Threaded Dispatch Processor)整体频率提升,这样曲面细分单元自然也会受益,同时GPU的几何处理能力会得到线性增强。
但是也有一种说法认为AMD没有能力在HD6000芯片的VLIW Core级别中添加更多的essellator单元,因为线程仲裁能力背后的设计还很复杂,比如足够的挂起空间。仲裁器本身没多少晶体管,这种资源基本上都是LDS,寄存器也是。所以R800使用了抢占式多线程,但是速度和效率还是得不到保障。
另一种猜想已经被我们否定,那就是在现有的前端超线程发送器(Ultra Threaded Dispatch Processor)中添加一个曲面细分单元(Tessellator)。因为这需要两套独立的crossbar,以及在VLIW Core外设置独立的出口,最后还要设置抢占式多线程分配单元。
所以我们可能看到HD6000系列在流处理器规模与HD5000系列相同的情况下,在Direct X 10和Direct X 9性能方面落后于HD5000,但是由于几何能力的提升,在Direct X 11方面,会有较为出色的表现。这一点和Fermi架构的设计思路是非常接近的。
在南岛架构完成之后,我们将见到相对于目前R600-R800转变较大的北岛架构(Northern Isl),根据现有的情报推断,北岛有可能是曾经的C1(代号Xenos架构)放大版。ATI可能会将RV8的US全部取出,把C1的3D+1D的流处理器和高速eDRAM放入核心。按照R600到R800以来的流处理器利用率,ATI认为4D+1D结构利用率很低,完全可以使用更灵活的搭配来减少晶体管消耗,这可以看做是一次向R300架构简洁明快设计思路的回归。
同时北岛架构的eDRAM不是做cache,是做全局存储,也就是我们看到的显存。2005年设计完成的C1(代号Xenos架构)所采用的eDRAM已经有250GB/s以上的带宽了。如果北岛架构使用现在的eDRAM,带宽翻倍甚至接近800GB/s都是可以做到的。当然使用高速eDRAM之后显存容量将会降低,也许我们看到北岛架构只有100MB左右的显存。不过用户不必担心纹理材质的存放问题,在Xenos时代借助eDRAM极高的带宽,整个XBOX360的GPU全局存储只有10MB。快速刷新显存实际上等效于显存容量的放大,加之高效的材质压缩算法,物理显存只要能够容纳最大材质就能满足GPU需求。
产品:ATI Radeon HD 4850 显示芯片
第三章:GPU通用计算发展与细节
● 第三章:GPU通用计算发展与细节
从世界上第一款GPU横空出世到今天,显卡已经走过了10年历史。GPU在这10年演变过程中,我们看到GPU从最初帮助CPU分担几何吞吐量,到Shader单元初具规模,然后出现Shader单元可编程性,到今天GPU通用计算领域蓬勃发展这一清晰轨迹。
这10年包含了无数设计者艰辛努力的成果,GPU也用自己的发展速度创造了半导体行业的奇迹,而GPU当今成就的见证者,正是我们的无数硬件玩家和游戏爱好者。我们可以肯定以GPU诞生初期的设计定位和市场需求,没有人敢相信今天GPU能走上通用计算这条道路,正所谓无心插柳柳成荫。
站在今天回看GPU通用计算历史,是GeForce2首开了GPU通用计算的先河,凭借其强大的多纹理处理性能,结合纹理环境参数和纹理函数可以实现一些很灵活的应用。GeForce2当时首先被用于求解数学上的扩散方程,成为GPU通用计算的最早应用。

Folding@home项目提供对ATI GPU产品支持
对GPU通用计算进行深入研究从2003年开始,并提出了GPGPU概念,前一个GP则表示通用目的(General Purpose),所以GPGPU一般也被称为通用图形处理器或通用GPU。随着GPU Shader单元计算能力的不断增长,一场GPU革命的时机也成熟了。
2005年,ATI改进型架构R580仅仅在晶体管数量只增加20%的情况下提供了相对R520 200%的Pixel Shader性能增长。其代表产品RADEON X1900XTX的FP32计算能力总共会是426.4 GFLOPS??R580因此得名“3:1黄金架构”。2006年,Folding@Home项目首先宣布提供对ATI Radeon X1900产品的支持。在显卡加入Folding@Home项目后,科研进展速度被成倍提升,人们第一次感受到了GPU的运算威力。

ATI Stream系列产品发展历史
在经历了R600的失落之后,2007年末新发布的代号RV670的Radeon HD 3000让我们看到了ATI的愿景和希望。这一代产品添加了双精度浮点能力支持,同时基于统一渲染架构的ATI Firestream 9000系列产品问世,用更小的集成度换取更高的浮点吞吐量已经成为ATI追求的目标,并行计算Firestream产品得到了硬件基础性支撑,编程环境和编译器优化稳步进行。
产品:ATI Radeon HD 4850 显示芯片
多核并行计算困惑与发展
● 多核并行计算困惑与发展
多核并行计算技术是当前计算机领域的研究热点。在未来数年内.随着芯片内核数量持续增长,多核计算将成为一种广泛普及的计算模式。它使计算机的计算能力显著提升,具有巨大的发展潜力和广阔的应用空间。当前,CPU主频的提升由于生产工艺和散热问题而受到严重的制约,处理器性能的改善已主要向着多核体系发展。
个人电脑使用者要想真正获得多核处理器带来的高效率,软件的发展必须跟上硬件的步伐,当前多核处理器软件总体滞后于硬件。传统的单线程串行计算软件只能导致多核的闲置,只有在算法设计及软件开发能够充分利用多核处理器的特性时,其优势才能真正体现出来。
在大规模并行计算领域,软件并不是并行化的制约趋势,传统架构的CPU无法获得更高的每瓦特性能才是致命伤,即使是使用了RISC架构处理器,超级计算机面对21世纪重大课题仍然显得手足无措。所以放大规模,换而言之为超级计算机添加更多的处理器或增加节点成为唯一可行的选择……
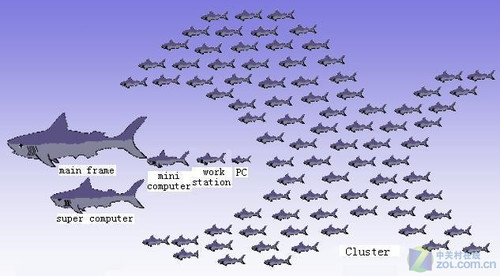
传统的超级计算机性能增长模式
在2003年单核心性能提升达到极限之时,2005年Intel和AMD共同在主流消费市场推出了旗下的双核心处理器,2007年推出4核心处理器,到现在Intel推出8核,AMD推出6核,PC机已经越来越像一个小型集群。但是与此同时,多核架构对现有的系统结构也提出新的挑战,如存储器壁垒、芯片、板极、系统级均衡设计以及可移植性等方面的问题。

每一台超级计算机几乎都配备了自己的发电站
2002年,一台耗资2.15亿美元的超级计算机在美国洛斯阿拉莫斯国家实验室运行,虽然它的运行速度高达30Tflops,但是为它提供各种制冷设备、冷却塔、空调、电源调节装置、变压器等辅助设施的建筑有好几座。这些迹象都预示着,更快的超级计算机的发展存在着一些限制,它们要求前所未有的电力供应,会产生越来越多的热量,其产生故障的机会也大增。超级计算机大约有1/3的电力支出用于散热,如果节点过密这个问题还会更加突出。
而在SIGGRAPH 2003大会上,许多业界泰斗级人物发表了关于利用GPU进行各种运算的设想和实验模型。SIGGRAPH会议还特地安排了时间进行GPGPU的研讨交流。与此同时,DirectX 9 Shader Model 3.0时代,新的Shader Model在指令槽、流控制方面的显著增强使得对应GPU的可编程性能得到了大大的提升。GPGPU的研究由此进入快车道。

GPU已经能够作为服务器模块
GPU被用于通用计算是经济发展的产物,也是历史的必然。首先传统CPU遭遇到频率提升困难,核心数目提升困难等一系列难题,同时大规模并行计算领域的性能需求越来越旺盛,传统性能增长模式无法延续下去。而此时的GPU拥有了可编程浮点执行单元、随后又通过整合多种着色器扩大了可编程浮点单元的规模和运算能力,再往前发展寄存器数量和调度能力增强让浮点精度得以完善,到现在我们看到基于GPU的超级计算机系统已经越来越多地出现在TOP500榜单上。
产品:ATI Radeon HD 4850 显示芯片
基于AMD CPU+GPU异构计算平台
● 基于AMD CPU+GPU异构计算平台
通过前文分析我们得知目前的主流计算能力来自CPU和GPU。CPU与GPU一般经北桥通过PCI-E总线连接,各自有独立的外部存储器,分别是内存与显存。在一些芯片组中使用的集成GPU没有独立的显存芯片,而是用内存中划出一部分充当显存。Intel在i3系列CPU中将一颗低端GPU核心集成到CPU基板上,但是受到功耗面积发热等限制,目前Intel还无法集成规模更大的GPU。AMD提出的Fusion计划第一步也是同样道理,既不可能将一颗性能级GPU集成到CPU中,也无法为这颗GPU提供独立的显存空间。

为游戏服务的CPU+GPU异构模式
传统的CPU+GPU异构模式是为图形运算服务的,典型应用是图形实时渲染。在这类应用中,CPU负责根据用户的输入和一定的规则(如游戏AI)确定在下一帧需要显示哪些物体,以及这类物体的位置,再将这些信息传递给GPU,由GPU绘制这些物体并进行显示。两者的计算是并行的,计算过程之间没有数据传递和分享;在GPU计算当前帧的时候,CPU可以计算下一帧需要绘制的内容。
在传统的CPU+GPU异构模式中,CPU负责的是逻辑性较强的事物计算,GPU则负责计算密集型的图形渲染。为了满足这类应用的计算需求,CPU的设计目标是使执行单元能够以很低的延迟获得数据和指令,因此采用了复杂的控制逻辑和分支预测以及大量的缓存来提高执行效率;而GPU必须在有限的时间内和有效的面积上实现很强的计算能力和很强的存储器带宽,因此需要大量执行单元来运行这些相对简单的线程,同时在当前线程等待数据的时候切换到另一个处于就绪状态的等待计算的线程。简而言之,CPU对延迟更敏感,而GPU则侧重于提高整体的数据吞吐量。CPU和GPU的设计目标不同决定了两者在架构和性能上有巨大差异。

AMD提供的CPU+GPU异构模式
CPU和GPU在以下几个方面有着重要的差异和特色:
1、CPU核心通常在一个时刻内只能运行一个线程的指令,CPU的多线程机制通过操作系统提供的API实现,是一种软件粗粒度多线程。当一个线程中断,或者等待某种资源时,系统就要保存当前线程上下文并装载另一个线程上下文。而GPU采用的是硬件管理的轻量级线程,可以实现零开销线程切换。GPU在自身并行度提高的情况下遇到越多的线程则可以用计算隐藏存储延迟。
2、主流CPU普遍拥有2个到4个核心,每个核心拥有3-6条流水线。这些核心使用了很多提高指令级并行的技术,如超标量深度流水线、乱序执行、分支预测、缓存管理等等,也使用了诸如SSE、3Dnow!等数据级并行技术。大量晶体管用于这些技术细节的实现,所以单个核心面积较大,数目无法做大。而GPU包含数目众多的拥有完整前端的小核心,如HD5870拥有320个VLIW Core,每个VLIW Core又可以看作是5个1D流处理器组成的SIMD处理器。GPU通用计算API可以利用多个VLIW Core之间的粗粒度任务级或数据级并行,以及VLIW Core内的细粒度数据并行。
3、CPU中的缓存主要是用于减小访问存储器延迟和节约带宽。缓存在多线程环境下会发生失效反应:在每次线程上下文切换之后,后需要上下文重建,这个过程耗费了大量时钟周期。同时为了实现缓存与内存的数据一致性,需要复杂的逻辑控制来实现一致性协议。ATI GPU内目前没有复杂的缓存体系与替换机制。它的GPU缓存是只读的,ATI认为目前应用中,GPU缓存的主要功能是用于过滤对存储器控制器的请求,减少对显存的访问。所以GPU缓存的主要功能不是用于减少延迟,而是节约显存带宽。

大量程序将会受益于ATI Stream GPU加速
AMD提出的CPU+GPU异构运算平台能够借此差异提供出色的整机性能,各部件能充分发挥自己的优势,处理拿手的应用,如传统的串行计算可以交给CPU负责,并行计算可通过AMD Stream流处理计算技术交给GPU运算。也就是说将来也多软件可利用GPU的大的性能为游戏、软件进行加速。目前支持AMD Stream的软件有AMD的AVIVO视频转换,而Adobe、ArcSoft、CyberLink等公司将来推出的软件将会加入AMD Stream的支持。
2009年末,AMD在面对当前的用户疑惑和对手宣传的GPU是系统核心等问题时曾经表示:“AMD的OpenCL for CPU Beta是下一代ATI Stream SDK中OpenCL开发平台的关键组成部分。预计新ATI Stream SDK将于今年晚些时候推出。我们是业界唯一一家同时提供CPU和GPU的厂商,在挖掘OpenCL潜力的道路上拥有独特的优势。通过支持OpenCL,ATI Stream技术将能够令开发者将运算负载灵活的划分到CPU或GPU上,更有效的执行程序。”
产品:ATI Radeon HD 4850 显示芯片
着色器模型变化历程与总结
● 着色器模型变化历程与总结
在图形渲染中,GPU中的可编程计算单元被称为着色器(Shader),着色器的性能由DirectX中规定的Shader Model来区分。GPU中最主要的可编程单元式顶点着色器和像素着色器。
为了实现更细腻逼真的画质,GPU的体系架构从最早的固定单元流水线到可编程流水线,到DirectX 8初步具备可编程性,再到DirectX 10时代的以通用的可编程计算单元为主、图形固定单元为辅的形式,最新的DirectX 11更是明确提出通用计算API Direct Compute概念,鼓励开发人员和用户更好地将GPU作为并行处理器使用。在这一过程中,着色器的可编程性也随着架构的发展不断提高,下表给出的是每代模型的大概特点。
表:Shader Model版本演化与特点
|
Shader Model |
GPU代表 |
显卡时代 |
特点 |
|
|
1999年第一代NV Geforce256 |
DirectX 7
1999~2001 |
GPU可以处理顶点的矩阵变换和进行光照计算(T&L),操作固定,功能单一,不具备可编程性 |
|
SM 1.0 |
2001年第二代NV Geforce3 |
DirectX 8 |
将图形硬件流水线作为流处理器来解释,顶点部分出现可编程性,像素部分可编程性有限(访问纹理的方式和格式受限,不支持浮点) |
|
SM 2.0 |
2003 年
ATI R300
和第三代NV Geforce FX |
DirectX 9.0b |
顶点和像素可编程性更通用化,像素部分支持FP16/24/32浮点,可包含上千条指令,处理纹理更加灵活:可用索引进行查找,也不再限制[0,1]范围,从而可用作任意数组(这一点对通用计算很重要) |
|
SM 3.0 |
2004年
第四代NV Geforce 6
和 ATI X1000 |
DirectX 9.0c |
顶点程序可以访问纹理VTF,支持动态分支操作,像素程序开始支持分支操作(包括循环、if/else等),支持函数调用,64位浮点纹理滤波和融合,多个绘制目标 |
|
SM 4.0 |
2007年
第五代NV G80和ATI R600 |
DirectX 10
2007~2009 |
统一渲染架构,支持IEEE754浮点标准,引入Geometry Shader(可批量进行几何处理),指令数从1K提升至64K,寄存器从32个增加到4096个,纹理规模从16+4个提升到128个,材质Texture格式变为硬件支持的RGBE格式,最高纹理分辨率从2048*2048提升至8192*8192 |
|
SM 5.0 |
2009年
ATI RV870
和2010年NV GF100 |
DirectX 11
2009~ |
明确提出通用计算API Direct Compute概念和Open CL分庭抗衡,以更小的性能衰减支持IEEE754的64位双精度浮点标准,硬件Tessellation单元,更好地利用多线程资源加速多个GPU |
传统的分离架构中,两种着色器的比例往往是固定的。在GPU核心设计完成时,各种着色器的数量便确定下来,比如著名的“黄金比例”??顶点着色器与像素着色器的数量比例为1:3。但不同的游戏对顶点资源和像素资源的计算能力要求是不同的。如果场景中有大量的小三角形,则顶点着色器必须满负荷工作,而像素着色器则会被闲置;如果场景中有少量的大三角形,又会发生相反的情况。因此,固定比例的设计无法完全发挥GPU中所有计算单元的性能。
顶点着色单元(Vertex Shader,VS)和像素着色单元(Pixel Shader,PS)两种着色器的架构既有相同之处,又有一些不同。两者处理的都是四元组数据(顶点着色器处理用于表示坐标的w、x、y、z,但像素着色器处理用于表示颜色的a、r、g、b),顶点渲染需要比较高的计算精度;而像素渲染则可以使用较低的精度,从而可以增加在单位面积上的计算单元数量。在Shader Model 4.0之前,两种着色器的精度都在不断提高,但同期顶点着色器的精度要高于像素着色器。
Shader Model 4.0统一了两种着色器,所以顶顶点和像素着色器的规格要求完全相同,都支持32位浮点数。这是GPU发展的一个分水岭;过去只能处理顶点和只能处理像素的专门处理单元被统一之后,更加适应通用计算的需求。
DirectX 11提出的Shader Model 5.0版本继续强化了通用计算的地位,微软提出的全新API??Direct Compute将把GPU通用计算推向新的巅峰。同时Shader Model 5.0是完全针对流处理器而设定的,所有类型的着色器,如:像素、顶点、几何、计算、Hull和Domaim(位于Tessellator前后)都将从新指令集中获益。

GPU执行FFT性能将在未来迅速提升
如图,快速傅里叶变换(Fast Fourier Transform,FFT)有广泛的应用,如数字信号处理、计算大整数乘法、求解偏微分方程等等。SIGGRAPH2008峰会认为未来随着Compute Shader和新硬件、新算法的加入,GPU执行FFT操作的性能将得到快速提升。
如果使用DirectX 11中的Computer Shader技术,API将能借助GPU充裕的浮点计算能力进行加速计算,则能轻易完成大量的FFT(傅里叶变换)。在图形渲染中,这项技术的运用极大地提高了波浪生成速度,而且画面质量也更好。
以往受限于浮点运算性能,目前CPU进行FFT变换只能局限在非常小的区域内,比如64x64,高端CPU最多能达到128x128,而GTX 280则能实现每帧512x512的傅里叶变换,所用时间不过2ms,效能非常高。
产品:ATI Radeon HD 4850 显示芯片
Shader计算能力快速发展
● Shader计算能力快速发展,灵活度不断提升
在图形渲染中,GPU中的可编程计算单元被称为着色器(Shader),着色器的性能由DirectX中规定的Shader Model来区分。GPU中最主要的可编程单元式顶点着色器和像素着色器。
为了实现更细腻逼真的画质,GPU的体系架构从最早的固定单元流水线到可编程流水线,到DirectX 8初步具备可编程性,再到DirectX 10时代的以通用的可编程计算单元为主、图形固定单元为辅的形式,最新的DirectX 11更是明确提出通用计算API Direct Compute概念,鼓励开发人员和用户更好地将GPU作为并行处理器使用。
图形流水线中可编程单元的行为由Shader单元定义,并可以由高级的Shading语言(例如NV的Cg,OpenGL的GLSL,Microsoft的HLSL)编写。Shader源码被译为字节码,然后在运行时由驱动程序将其转化为基于特定GPU的二进制程序,具备可移植性好等优势。传统的图形渲染流线中有两种不同的可编程着色器,分别是顶点着色单元(Vertex Shader,VS)和像素着色单元(Pixel Shader,PS)。表一和表二比较详细地罗列出从Shader 2.0到Shader 4.0像素着色单元和顶点着色单元的演进过程。
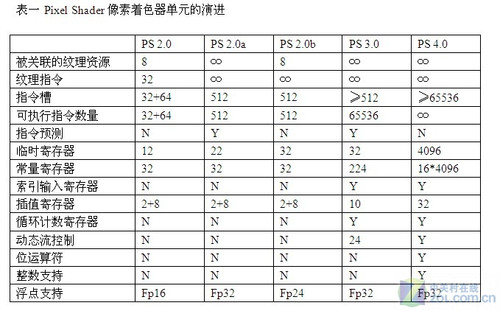
表一 Pixel Shader像素着色器单元的演进
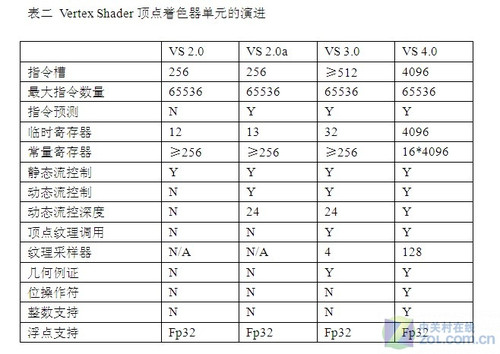
表二 Vertex Shader顶点着色器单元的演进
表中:PS 2.0 = DirectX 9.0 original Shader Model 2 specification。
PS 2.0a = NVIDIA Geforce FX-optimized model。
PS 2.0b = ATI Radeon X700 X800 X850 shader model,DirectX 9.0b。
PS 3.0 = Shader Model 3。
PS 4.0 = Shader Model 4。
N = NO,Y = YES。
“32+64”指32个纹理指令和64个算术指令。
产品:ATI Radeon HD 4850 显示芯片
揭秘GPU高性能计算关键
● 揭秘GPU高性能计算关键
高性能计算并不是纯数据吞吐,也不是纯计算密集型任务,它对计算机硬件拥有较为复杂的要求。所以单独提升单线程能力不能解决高性能并行计算需求,单纯堆积流处理器数量也无法适应未来的数据和指令环境。CPU和GPU都必须做出改变,但是我们明显能够感觉到GPU改变的代价小于CPU特别是X86架构的CPU。基本上每隔一年,GPU的架构体系就会发生一次转变,而每两代转变则代表计算能力的一次飞跃。
有效地运用计算资源的财富要涉及到多个重要目标。首先必须合理组织计算资源,使得重要的数据和指令类型获得较高的加速比。同时大量提供计算单元还远远不够;必须实现高效的通信、高效的线程管理,充足的寄存器与前端资源……这样才有可能让流处理器尽可能地被数据填充而不浪费。我们将GPU高性能计算的关键分为以下几个部分来分析:

典型的CPU内部功能单元
1、高效的计算方法
GPU核心上可以放下上百个计算单元。为了计算的目的架构设计师必须最佳利用晶体管的关键是使致力于计算的硬件最大化,并且允许多个计算单元通过并行同时操作,而且保证各个计算单元以最大效率操作。
虽然现在的半导体制程技术允许在单个芯片内放置大量晶体管以提升单核心性能或提升并行度,但资源不是无限的。我们可以广义地将晶体管的用途划分为3类:控制类(这些晶体管用于指挥操作);数据通路(Datapath,这些硬件用来执行计算);存储类(这些硬件用于存放数据)。
在数据通路之内,可以允许在相同时间的并发操作。这种技术被称为并行性。我们可以构想几个方式以利用并行性和允许同时执行。复杂的任务比如图形处理,一般由几项连续的任务组成,当运行这些应用时,我们能够在不同的数据上同时运行几个这样的任务(任务并行性)。在一个阶段之内,如果在几个数据元素上执行一个任务,我们能够利用数据并行性同时对数据求值。而在一个数据元素的复杂求值之内,能够同时求值几个简单操作(指令并行性)。
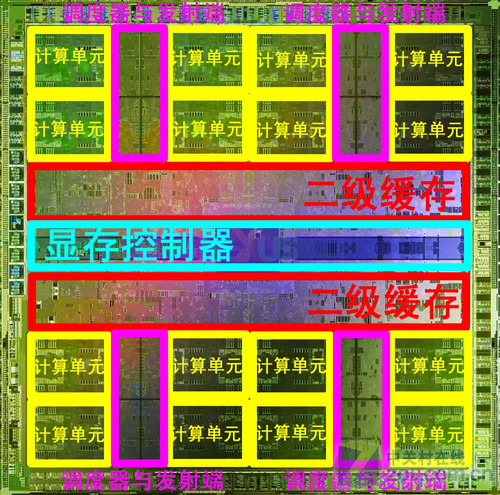
Fermi架构GPU内部功能单元
2、高效的通信方法
GPU芯片外的存储器速度总是无法跟上GPU算术能力的增长幅度,所以作为一颗高性能处理器,GPU必须要想办法突破这道“存储器墙”,必须尽量减少芯片外通信以节能带宽降低延迟。为了逼近终极目标“消灭片外通信”,也就是尽量只在芯片内部进行数据通信,芯片外通信只用于获取或者保存真正的全局数据。
在GPU内部加入Cache是一种有效的方式:最近使用的数据的副本可以由存储器传递到Cache中并根据替换协议不断更改。Cache由于对晶体管消耗较大,缓存协议难以实现,一直是GPU设计的重要障碍之一。比如在GPU上经过几代尝试已经成熟的Texture cache可以存放纹理,又如NVIDIA在G80架构中加入的Shared Memory和AMD在RV770架构加入的LDS(Local Data Share)。这个共享寄存器位于每个流处理器单元内部的所有运算单元中,它在通用计算时负责共享数据和临时挂起线程。容量足够大的共享缓存可以在运算时提高线程的挂起能力,还有很多东西比如乱序,分支等等都会受益于Cache的加入。
产品:ATI Radeon HD 4850 显示芯片
CPU与GPU的区别和发展方向
● CPU与GPU的区别和发展方向
GPU作为今天的高性能处理器在设计方面已经和以往的图形流水线有着不同的目标,它已经开始瞄准通用计算程序。一般来讲,这类程序相对于图形运算的并行度不是很整齐,甚至并行度有所下降,需要较为复杂的控制和较低的性能目标。
CPU编程模型一般是串行的,在它们的应用程序中不会充分地利用数据并行性。CPU硬件反应了这种编程模型:在常见的情况中,CPU在同一时刻只处理一个数据,不利用数据并行性。而最近几年的SSE和最新的AVX指令集提高了数据并行执行能力,但是CPU所利用的并行程度还是远小于GPU。
并行硬件在CPU数据通路中较不流行的一个原因是设计者把更多的晶体管用于控制硬件。CPU程序比GPU程序所要求的控制要复杂很多,多以CPU的晶体管和连线有很大一部分用于实现复杂的控制功能,如分支预测和乱序执行。结果CPU的核心只有很少一部分用于运算。由于CPU的目标是通用程序,所以它们不为特殊功能包含专门的硬件。而GPU可以为特殊任务实现专用硬件结构,这些固定功能单元远比通用可编程方案提供的效率高的多。我们可以从上一页的两张图片中看出CPU和GPU对晶体管的使用。
最后,CPU内存系统被优化为极小的延迟而不是GPU内存系统瞄准的最大吞吐量。由于缺乏并行性,CPU程序必须尽快返回内存以继续前进。结果,CPU内存系统包含几级Cache以最小化延迟。然而Cache对很多数据类型是无效的,包括图形输入和只访问一次的数据。对于图形流水线,为所有元素最大化吞吐量而不是为所有元素最小化延迟,会提升内存系统的使用率和高性能计算的整体实现。
每代新硬件对于GPU厂商来说都是一个挑战:他们如何有效地使用附加的晶体管资源来增加性能和功能?新的晶体管增量将致力于增加性能,但是架构师必须清醒地认识到这些晶体管该如何给运算单元、控制单元和存储单元分配以达到最佳效能。如果不能平衡这种压力,或者对未来的应用分析导致整个设计思路发生偏差,那么对于下一代GPU产品将是很严重的打击。
GPU的功耗增长同样是可怕的问题,2003年上市的GeForce FX 5800 Ultra是第一款遇到功耗问题的GPU,或者说业界第一次感受到功耗问题的严重性。此后的大芯片设计还有Radeon X1900和DirectX 10时代的大部分芯片。ITRS从2003年开始大家力度关注功耗对于芯片设计的影响,而2009年的报告已经将逻辑器件的按比例缩小引起的漏电、短沟效应、材料适应性等问题列为半导体设计面临的严峻考验。而GPU作为数倍超越摩尔定律发展的大型芯片,其表现更加令人担忧。

几何与渲染代表了GPU的两大功能区
在可编程性方面,虽然近几年的GPU设计已经足够多的照顾到了并行计算领域的需求,但是GPU的可编程性仍然较弱。从数量上说,统一渲染着色器(Unified Shader)和固定功能单元(Fixed Function)是GPU的两个主要部分,而大部分固定功能单元是无法可编程利用的。从深度来来说,虽然我们在NVIDIA新开发的Fermi架构中看到了统一定址和全能缓存等设计,但是GPU所能够涉及到的并行计算程序仍然需要使用专门的API和较为低级的语言开发,程序员对于运用GPU的缓存和其他特性仍然显得手足无措,更何况还要避免分支的出现和适应复杂的GPU存储体系。
从发展历程来看,GPU已经包括了原先属于CPU的功能。早期的消费级图形硬件在图形处理器上甚至无法执行几何处理,今天已经能够借助固定功能单元来实现了。虽然GPU功能主要增加方向是图形流水线中的可编程性,但是GPU设计者仍然在把更多功能放在GPU上执行。尤其是今天的游戏需要大量的物理特效和人工智能计算或者图像后处理(Post Process)。这些计算任务在GPU上完成拥有更高的加速比,是相当有吸引力的。
未来的高性能处理器市场将因为GPU的飞速发展变得更有看点,当GPU将越来越多原来在CPU上的应用转移到自己身上时,CPU也不会停滞不前。虽然它拥有较高的通用性,但是CPU的并行能力也在提升,这种提升不会停滞不前。未来CPU与GPU厂商的冲突将会愈演愈烈。计算机系统的资源分配是偏向CPU还是GPU?GPU是否会因为通用性的提高而替代CPU?还是CPU也变身为几百个核心的高能处理器来对抗GPU?这些令人兴奋的问题将会是未来处理器体系结构设计者面临的重要选择。
产品:ATI Radeon HD 4850 显示芯片
如何将GPU功能单元映射为通用单元
● 如何将GPU功能单元映射为通用单元
基于GPU的计算从概念上讲很容易理解,并且现有多种高级语言和软件工具可以简化GPU的编程工作。但是开发人员必须首先了解GPU在图像绘制过程中是如何工作的,然后才能确定可用于计算的各个组件。为了着手把一般性的计算映射到GPU的专用硬件中,必须先确定GPU提供的各种计算资源,下面我们将简单了解GPU通用计算中各硬件系统的作用。以下资料由英国NVIDIA公司的开发工程师Mark Harris提供。

NVIDIA和ATI的GPU流处理器设计
可编程并行处理器:GPU有两类可编程处理器,即三角顶处理器和像素处理器。顶点处理器负责处理顶点数据流(由位置、颜色、标准向量和其它属性),它们是组成三维几何模型的元素。依据每个顶点相对于其视点的位置,顶点处理器用顶点渐变程序对其转换。
像素处理器将像素渐变程序用于处理每个输出像素以确定其最后的颜色。顶点处理器和像素处理器是完全可编程的,可以对四个不同的数值同时执行一条指令。这是因为图形的基本要素或者是位置(X、Y、Z、W)或者是颜色(红、绿、蓝、alpha)。

ATI最为喜欢的SIMD结构流处理器
光栅处理器:在顶点处理器转换完顶点之后,每三个一组的顶点就用来计算一个三角形。从这个三角形出发,光栅处理器生成一个像素流。该光栅处理器的功能非常专一,就是表现这些三角形,因而不是用户可编程的,但可将它看成是一个地址内插器和一个数据放大器(因为它根据几个三角顶就可生成许多像素)。
纹理单元:顶点处理器和像素处理器能以纹理(图像)的形式访问存储器。该纹理单元可被看成是一个只读存储器接口。当前的GPU可以将一个输出图像写到纹理结构存储器,而不是写到帧缓存器。这个纹理渲染功能是基本的,因为它是将GPU输出直接反馈到输入的唯一现有机制,这个过程无须返回到宿主处理器。纹理渲染可被看成是一个只写存储器接口。

本次Fermi架构显卡所使用的CUDA运算核心
数据类型:当涉及数据类型时,现有的GPU比CPU更受限制。它们只支持定点或浮点形式的实数。如果没有一些图形编程方面的知识,初涉GPU编程可能会感觉麻烦。在CPU和GPU之间做某些非常简单的类比是有益的。
GPU纹理 = CPU矩阵:GPU上的基本矩阵数据结构是纹理(图像)和顶点矩阵。在CPU上用到一个数据矩阵的地方,也就是在GPU上用到一个纹理的地方。
GPU渐变程序 = CPU内循环:在CPU中,一个循环可重复用于一个数据流(存在一个矩阵内)内的各个元素,用该循环体内的各条指令处理这些元素。在GPU中,类似的指令可写在一个渐变程序之内,并自动应用到相应数据流的所有元素上。在这个计算中并行处理的数量取决于该GPU中处理器的数量。
纹理渲染 = 反馈:为了在GPU中实现反馈,纹理渲染功能必须用来将一个碎片程序的结果写到存储器中,该存储器随后可用做未来其它程序的输入。
几何光栅 = 计算启动:为了启动GPU中的计算,只需画个简单的几何图形。顶点处理器将转换它,而光栅单元将决定它所涉及的输出缓存器中的像素值,并为每个元素产生一个碎片。由于表示一个矩阵的方形碎片流中的每个元素一般都要经过处理,因此在GPU编程中启动通用计算最常见的手段就是用一个方块。
产品:ATI Radeon HD 4850 显示芯片
分支对GPU结构体系的挑战
● 分支对GPU结构体系的挑战
分支和循环是最基本的流程控制,也是编程中最基本的概念。我们知道CPU是为单线程程序运行加速而设计的,GPU是为并行程序设计的。首先CPU是指令并行,只有指令间并行的架构才需要分支预测,而GPU是线程间并行,指令按顺序发射,没有分支预测。所以当GPU遇到分支问题时,性能会发生较大的变化,而且不同架构的性能变化幅度也不一样。
GPU起初是为了3D渲染设计的,涉及到大量同类型平行数据计算,数据吞吐量很大,因此GPU内部包含了大量的核心(抑或叫处理单元)以满足这种需求;相反的,CPU设计侧重于通用应用,其中很大一部分晶体管用于逻辑控制单元和缓存,适用于繁琐的计算。例如CPU控制单元可以分支预测,推测执行,多重嵌套分支执行(if条件判断等等),而GPU计算的时候则将数据全部扔进着色器核心运算输出,GPU内没有流水线,因此无法实现乱序执行等技术,同时GPU的分支能力是靠线程挂起来实现的,换而言之是频繁的线程切换把分支延迟都给掩盖了。
让我们通过一段简单的程序来了解分支的概念:
If (a)
b=f()
else
b=g()
b=f()
else
b=g()

一个典型的条件分支程序示意图
CPU可以容易地基于布尔变量a来求f()或g()函数。这种分支的性能特征相对容易理解:CPU内有相对较长的流水线和专门的功能单元,因此CPU能够正确地预测是否会采用一个特定的分支。如果这个预测能够成功地完成,通常分支会导致较小的损失。
而GPU没有这种功能单元,但是也可以进行分支运算的操作,而且分支在遇到不同结构的流处理器体系时表现的性能也是有很大差异的。在单指令多数据流(SIMD)的结构中,单一控制部件向每条流水线分派指令,同样的指令被所有处理部件同时执行。另外一种控制结构是多指令多数据流(MIMD),每条流水线都能够独立于其他流水线执行不同的程序。
从GeForce 6800 Ultra开始,NVIDIA公司GPU内部的顶点着色器流水线使用MIMD方式控制,像素着色器流水线使用SIMD结构,而AMD则一直全部使用SIMD结构。MIMD能比较有效率地执行分支程序,而SIMD体系结构运行条件语句时会造成很低的资源利用率。不过SIMD需要硬件少,可以大量添加运算单元,这是一个优势。

在每一个VLIW Core之内都有一个分支单元
GPU可以通过线程分配器+各种临时资源的挂起能力来完成动态的线程分配,一旦某线程当前无法完成就把它挂起而不用等着,等它可以被完成了再送去其他单元进行处理,这是周边资源充足之后可以很轻松实现的东西。GPU内部的每个处理单元都不会闲着,处理不来马上换下一个线程,但这不是标准的乱序执行。乱序要和流水线衔接的,使流水线没有空闲是其目的。GPU中每个SP都是一个1级流水线的东西,流水线只能满载。所以CPU的乱序执行技术是流水线防欠载的手段,而GPU则是处理单元防欠载。这种宏观上的动态的线程分配和挂起能力决定了GPU可以利用计算来掩盖存储进行分支操作。
产品:ATI Radeon HD 4850 显示芯片
GPU与CPU将如何演绎融合与吞并
● GPU与CPU将如何演绎融合与吞并
通用处理器(CPU)经过几十年发展,Intel、AMD脚步越来越慢,处理器性能提升越来越小。反观GPU潜力无限,性能提升空间巨大。CPU着重于通用运算,而GPU则对矩阵和并行运算更加在行,若是将这两者整合起来必定会带来处理器发展的新纪元。
就一般通用处理器来说,在大规模并行处理方面性能远不如GPU。我们可以通过让GPU运行并行度高计算密集的程序,将GPU的优势发挥出来,使其性能得到大幅提高。从更深层次考虑,目前CPU性能提升遇到了各种各样的困难,除了难以攀升的核心频率之外,核心架构效率、核心数量都很难获得大幅提升。反观GPU就是一番不同的景象了,它的潜力还未被完全的挖掘,提升空间巨大。
在这一部分我们着重分析3款跨时代的并行计算产品的特性和发展状况,而下一章节我们会深入分析其架构特点。
首先要登场的是Larrabee芯片,这是一款由多个小型X86内核组成的并行计算处理器。它最早于2007年的秋季IDF提出,是Intel在X86架构与GPU类向量处理器架构之间做出精确衡量的产品。它的主要技术特色有X86架构核心、顺序执行单元和多核心技术与CSI总线等几大看点。Larrabee因为其可编程性优越,而特别被市场和用户所关注。

Intel对于未来计算趋势的认识
Intel使用CPU经典原理和最新技术改良了传统GPU,使其集成了数目可观的X86核心,并采用顺序执行,同时辅以先进的CSI总线和高速存储系统,形成了Larrabee芯片概念。Larrabee芯片隶属于Tera-Scale项目,是一块融入的诸多先进技术的GPU。对于图形工业而言,Larrabee是一款具有革命意义的产品,它与常规的意义上的GPU存在理念上的差异,即Larrabee将通用计算性能放在优先位置。Intel高级副总裁Pat Gelsinger表示,Larrabee是一种可编程的多核心架构,采用顺序执行架构(CPU为乱序执行核架构),并使用经过调整的x86指令集,在运算性能上将达到万亿次浮点运算的级别。
相对于传统领域,Fusion则是我们更关注的。早期的GPU是用类似OpenGL或Cg的图形API编程的,这些API很难且大多数开发人员也不熟悉。另外,由于GPU内部缓存远远小于CPU,它只能执行预定好的任务,并不能像CPU那样去执行自定义的任务。这个状况在NVIDIA和AMD的新产品上发生了很大转变,但GPU还是不能染指CPU的领域。基于这个原因,AMD认为NVIDIA不会马上成功,Intel在没有高端图形芯片时也不能威胁到自己,但面对未来应用,必须将CPU与GPU紧密结合,各取所长。

AMD对于Fusion APU融合架构的畅想
2005年10月25日,在AMD收购ATI后,随即发表代号为Fusion(融合)的研发计划,Fusion预计将AMD的CPU与ATI的GPU整合在一起,同时也将北桥芯片也一并纳入。初期的Fusion将简单整合CPU与GPU到一个芯片中,最终产品CPU和GPU将彻底融合,互相使用其物理资源构成强大而特殊的逻辑芯片成为APU(Accelerated Processing Unit)。
NVIDIA同样对并行计算市场充满期待并且在实践着自己的计划,今年推出的Fermi架构处理器就是其战略目标的重要一步。Fermi的众多特性,已经明明白白告诉用户,这不是仅为游戏或者图形运算设计的GPU,而是面向图形和通用计算综合考虑的成果。全局ECC设计、可读写缓存、更大的shared memory、甚至出现了分支预测概念……这次Fermi抛弃长期使用的“流处理器”称谓方式,更明确体现了NVIDIA的意图。

Fermi处理器架构要点
代号GF100的Fermi设计方案在4年前确定下来并付诸行动,这时正值代号G80的Geforce 8800GTX做最后的出厂准备。G80凭借全新的MIMD(多指令流多数据流)统一着色器(又称流处理器)获得了业界的一致认同,同时被业界关注的还有G80的通用计算性能。NVIDIA的Tony Tamasi先生(NVIDIA高级副总裁,产品与技术总监)表示:“以前的G80架构是非常出色的图形处器。但Fermi则是一款图形处理同样出色的并行处理器。”从SIGGRAPH 2003大会首先提出GPU通用计算概念,到NVIDIA公司2007年推出CUDA平台,再到今天Fermi架构面向通用计算领域设计。越来越多的信号告诉我们,GPU通用计算是一片正在被打开的潜力巨大的市场。
产品:ATI Radeon HD 4850 显示芯片
第四章:GPU内部计算实现细节
● 第四章:GPU内部计算实现细节
从并行计算演变的角度来看,伴随着PC级微机的崛起和普及,多年来计算机图形的大部分应用发生了从工作站向微机的大转移,这种转移甚至发生在像虚拟现实、计算机仿真这样的实时(中、小规模)应用中。这一切的发生从很大程度上源自于图形处理硬件的发展和革新。近年来,随着图形处理器(GPU)性能的大幅度提高以及可编程特性的发展,人们首先开始将图形流水线的某些处理阶段以及某些图形算法从CPU向GPU转移。
除了计算机图形学本身的应用,涉及到其他领域的计算,以至于通用计算近2~3年来成为GPU 的应用之一,并成为研究热点。GPU内部有众多参与图形计算的功能单元,正如我们在前文中看到的,其中大多数浮点单元由于具备可编程性而成为通用计算单元。在本章,我们将分析当前最受关注的几种GPU架构和这些架构中的晶体管分配差异和整数与浮点运算的实现情况。

单核心CPU,多核心CPU与异构计算发展阶段
在SIGGRAPH 2003大会上,许多业界泰斗级人物发表了关于利用GPU进行各种运算的设想和实验模型。SIGGRAPH会议还特地安排了时间进行GPGPU的研讨交流。与此同时,DirectX 9 Shader Model 3.0时代,新的Shader Model在指令槽、流控制方面的显著增强使得对应GPU的可编程性能得到了大大的提升。GPGPU的研究由此进入快车道。2003年被认为是图形硬件被用来做通用计算的一个里程碑。大多数文献也认为GPU在2003年已经进入计算的主流.采用图形硬件来做通用计算的主要目的是为了加速,加速的动力来自这些新硬件所具有的以下主要优势:
(1)一定的并行性:这一功能主要是通过多个渲染管道和RGBA 4个颜色通道同时计算来体现的,另外在一个时钟周期内可以同时获取2个甚至更多副纹理.顶点程序的多个渲染管道意味着一个时钟周期可以并行处理多个顶点,而对于像素程序同样如此.相对于并行机而言,图形卡提供的并行性虽然很弱,但它在十分廉价的基础上为很多应用提供了一个很好的并行方案,尤其是对于图形本身的应用来说。
(2)高密集的运算:由于图形卡内部的内存接口位宽大于CPU上的位宽,如Radeon HD2900XT的内存位宽达512位,显然高于CPU上64或者双通道128位的位宽,这样整个计算的带宽大大提高.GPU相对于CPU来说,更适应传输大块的数据,虽然CPU上有Cache可以加速整个计算过程,但CPU上的Cache相对于图形卡显存来说太小,一般只有6MB左右,而现在的显存大多都在1024MB以上,最新的GPU中同样出现了768KB可读写缓存,由此可见一斑。
(3)减少了GPU与CPU的数据通信:尤其是当整个应用针对图形生成的时候,不再需要在CPU与GPU之间进行多次数据交换,从而可以将CPU解放出来做其他的事情.这些优势使得GPU 比CPU更适用于流处理计算,因此GPU也被认为是一个SIMD的并行机或者流处理器,可以用于处理大规模数据集,使得应用得到加速。相比之下,CPU本质上是一个标量计算模型,而计算单元偏少,主要针对复杂控制和低延迟而非高带宽进行了若干优化。

X86架构CPU与GPU之间的异同
现阶段我们看到了从R600到R800时代,ATI历经3年时间通过不断改进架构(放大规模与优化内部结构并重),获得了前所未有的浮点吞吐性能和业界最高的性能功耗比。同时我们通过NVIDIA设计的Fermi架构已经看到了GPU并行计算继续向前向更深入的领域发展,虽然第一代GF100核心由于受到了现阶段半导体工艺的限制并不十分完美,但是第二代GF104核心表现出色。
Intel也抓紧一分一秒来推进自己的并行计算产品,几天前Intel对外发布了一款名为“Knights Ferry”的服务器处理器。该处理器使用了Intel当前最先进的32nm工艺技术,拥有数量庞大的32颗核心,主频也已经达到了较高的1.2GHz。据Intel总裁兼数据中心群组总经理Kirk Skaugen表示,“Knights Ferry”是目前Intel推出的最快处理器。通过我们对这款产品的分析得知,“Knights Ferry”正是就是束之高阁的Larrabee。
产品:ATI Radeon HD 4850 显示芯片
GPU主要计算单元分布和职能
● GPU主要计算单元分布和职能
为了把通用的计算映射在GPU的专用硬件上,我们应该首先熟悉GPU所提供的运算资源。在统一渲染架构提出之前,GPU内部有两种可编程处理器,分别是顶点处理器和像素处理器,在图形运算中我们将它们称为Pixel Shader(顶点着色器)、Vertex Shader(像素着色器)。由于目前ATI R600到R800架构一直在使用Pixel Shader(顶点着色器)所代表的SIMD结构流处理器,而NVIDIA G80到GF100一直在使用Vertex Shader(像素着色器)所代表的MIMD结构流处理器,所以我们借助一些图片来为大家拆分GPU着色器单元的原理。
顶点处理器处理顶点流(由位置、颜色、法线向量和其他属性组成),这是组成多边形几何模型的元素。计算机图形一般用三角形网格来表示3D物体。顶点处理器应用一个顶点程序(也可以称为顶点着色器)根据相对摄像机的位置来转换每个顶点,然后每组3个顶点用来计算一个三角形,由此产生了片段流。

顶点如何表示三角形图元
可以认为片段是“原始像素”,它包含的信息用来在最终图形中产生一个着色的像素,包括颜色、深度和在显存区内的目的地。像素处理器将一个片段处理器(也可以称作像素着色器)应用到流中的每个片段,用来计算每个像素的最终颜色。
1、传统意义中的顶点处理器(MIMD结构)
由于图形运算具备较高的并行度,所以GPU内部都有多个顶点处理器。这些处理器是完全可编程的,而且ATI和NVIDIA都选择了以MIMD并行的方式操作输入顶点。3D计算机图形基本图元是投射空间中的3D顶点,表示为一个四元组(x,y,z,w)的向量,四维的颜色存储为四元组(red,green,blue,alpha)的向量(通常缩写为R,G,B,A),其中Alpha一般表示透明的百分比。
2、传统意义中的像素处理器(SIMD结构)
和顶点处理器一样,GPU中也包含大量并行的像素处理器,这些处理器也是完全可编程的。像素处理器以SIMD的并行形式操作输入元素,并行地处理四维向量。像素处理器有能力获取来自纹理的数据,因此它们可以进行聚集。但是像素输出地址总是在像素处理之前,也就是说处理器不能改变像素的输出位置。因此像素处理器不能进行散布。

两种单元的组织形式
这里所说的聚集(Gather)和散布(Scatter)是讨论在GPU上进行数据通信时提出的概念,它们是GPU两种主要的通信类型。聚集发生在当处理一个流元素时还需要其他流元素的信息,它聚集来自存储器其他部分的信息。另一方面散布发生在当处理一个流元素的时候把信息信息分布到其他流元素,它把信息“散布”到存储器的其他部分。
现代GPU通用计算程序中,适应于SIMD结构流处理器的程序比MIMD结构要多,因此这种结构可以有效处理吞吐需求较量大的并行度较高的数据类型,但是一旦遇到分支等因素的影响,MIMD的衰减要明显小于SIMD结构,所以MIMD结构可以更好地使用复杂数据与指令结构。
3、光栅器与纹理单元
在顶点处理器转换顶点之后,每组3个顶点都用于计算一个三角形,从这个三角形产生一个片段的流。产生片段的工作由光栅器(ROP单元)完成,光栅器可以认为是一个地址插值器或者是一个数据放大器。光栅器的这些功能专用于渲染三角形,而且用户是不可编程的。
像素处理器(TMU单元,由Texture Address 和Texture Filtering组成。翻译为:纹理定址单元和纹理拾取单元)可以以纹理的形式访问存储器。我们可以把纹理单元想象成一个只读的存储器接口,存储器读和写在GPU上是完全分开的。
产品:ATI Radeon HD 4850 显示芯片
GPU内部通用计算代码运算过程
● GPU内部通用计算代码运算过程
CPU与GPU在编程方面到底有哪些联系和区别,如何将原有CPU编程概念和GPU硬件概念相对应?相信这对于一位对GPU并不十分了解的程序员还是相当困难的,这一节我们通过对应传统的CPU计算概念和他们对应的GPU概念上做一些非常简单的类比来帮助用户理解这一点。
GPU纹理=CPU数组:在GPU上的基本数据数组结构是纹理和顶点数组。对于GPGPU来说,SIMD结构的流处理器比MIMD结构流处理器更为易用同时拥有更高分值。在任何会在CPU上使用数据数组的地方,都能在GPU上使用纹理。
GPU片段程序=CPU“内循环”:GPU的很多并行流处理器是它们的计算部件??它们在数据流上执行核计算。在CPU上,会使用一个循环来迭代流的元素,串行序列化地处理它们。在CPU的情况中循环内的指令是核。而在GPU上,在一个片段程序中写相似的指令,它们会被应用到流的所有元素。在这个计算过程中,并行数量取决于使用的GPU上有多少个流处理器,以及是否能够很好地利用GPU计算指令提供的四维向量结构的指令并行性。
渲染到纹理=反馈:大多数计算在GPU内部被拆解为很多步,每一步都依赖前一步的输出。在CPU上这些反馈都是微不足道的,因为它的存储器模型是统一的,它的存储器可以在程序中的任何地方被读或者写。而GPU为了反馈,必须使用渲染到纹理这个过程,把片段程序的结果写入存储器,然后才可以把后面的程序输入。
几何体光栅化=计算调用:为了执行一个程序,还应该知道该如何计算,而不止是数据表示、计算和反馈。为了计算调用,只需要绘制几何体。顶点处理器将会转换几何体,而光栅器将会决定它在输出缓冲区中覆盖了哪些像素,并为每一个像素产生一个片段。在GPGPU中,一般处理片段的矩形流中的每个元素,他们表现成一个栅格。因此在GPGPU中编程最常见的一个调用是一个四边形。
在绘制图像时,GPU首先接收宿主系统以三角顶点形式发送的几何数据。这些顶点数据由一个可编程的顶点处理器进行处理,该处理器可以完成几何变换、亮度计算等任何三角形计算。接下来,这些三角形由一个固定功能的光栅器转换成显示在屏幕上的单独“碎片(fragment)”。在屏幕显示之前,每个碎片都通过一个可编程的碎片处理器计算最终颜色值。
计算碎片颜色的运算一般包括集合向量数学操作以及从“纹理”中提取存储数据,“纹理”是一种存储表面材料颜色的位图。最终绘制的场景可以显示在输出设备上,或是从GPU的存储器重新复制到宿主处理器中。

两向量相加的简单Brook代码示例
图为执行两向量相加的简单Brook代码示例。Brook支持所有带附加流数据的C句法,流数据存储于GPU的存储器中,而核函数也在GPU上执行。可编程顶点处理器和碎片处理器提供了许多相同的功能和指令集。但是,大部分GPU编程人员只将碎片处理器用于通用计算任务,因为它通常提供更优的性能,而且可以直接输出到存储器。
利用碎片处理器进行计算的一个简单例子是对两个向量进行相加。首先,我们发布一个大三角形,其所包含的碎片数量和向量大小(容纳的元素)相同。产生的碎片通过碎片处理器进行处理,处理器以单指令多数据(SIMD)的并行方式执行代码。进行向量相加的代码从存储器中提取两个待加元素,并根据碎片的位置进行向量相加,同时为结果分配输出颜色。输出存储器保存了向量和,这个值在下一步计算中可以被任意使用。
可编程碎片处理器的ISA类似于DSP或Pentium SSE的指令集,由四路SIMD指令和寄存器组成。这些指令包括标准数学运算、存储器提取指令和几个专用图形指令。
产品:ATI Radeon HD 4850 显示芯片
认识GPU浮点计算精度
● 认识GPU浮点计算精度
DirectX 9.0时代提出的Shader Model 2.0最重要的一点改进是增加对浮点数据的处理功能,以前GPU只能对整数进行处理,改进后提高渲染精度,使最终处理的色彩格式达到电影级别。Shader Model 2.0时代突破了以前限制PC图形图象质量在数学上的精度障碍,它的每条渲染流水线都升级为128位浮点颜色,让游戏程序设计师们更容易更轻松的创造出更漂亮的效果,让程序员编程更容易。而从通用性方面理解,支持浮点运算让GPU已经具备了通用计算的基础,这一点是至关重要的。
如果说DirectX 8中的Shader单元还是个简单尝试的话,DirectX 9中的Shader则成为了标准配置。除了版本升级到2.0外,DirectX 9中PS单元的渲染精度已达到浮点精度,传统的硬件T&L单元也被取消,在较低DirectX版本游戏运行时会使用VS单元模拟执行硬件T&L单元的功能。

浮点处理器能够统一执行多种任务
后来统一渲染架构提出进一步提高了着色器的运算效率,Pixel Shader(顶点着色器)、Vertex Shader(像素着色器)和Geometry Shader(几何着色器),三种具体的硬件逻辑被整合为一个全功能的着色器Shader。程序员不必为了两种结构不同的着色器分别编写程序,GPU内部的可编程单元被抽象为浮点处理器(Floating Point Processor)。
一个浮点数a由两个数m和e来表示:a = m × be。在任意一个这样的系统中,我们选择一个基数b(记数系统的基)和精度p(即使用多少位来存储)。m(即尾数)是形如±d.ddd...ddd的p位数(每一位是一个介于0到b-1之间的整数,包括0和b-1)。如果m的第一位是非0整数,m称作规格化的。有一些描述使用一个单独的符号位(s 代表+或者-)来表示正负,这样m必须是正的。e是指数。关于浮点数表示法,我们可以通过看下面的表达式来理解:
Sign×1.matissa×2(exponent-bias)
我们可以将其套用在数143.5的表示上,这对应科学计数法的1.435×102。科学计数法的二进制表示是1.00011111×2111。因此底数被设为00011111(前导的1被省略),将指数偏移127来存储(由特定的浮点格式标准设置),也就是10000110。
不同的浮点格式用不同的位数来表示底数和指数,例如IEEE754标准中,一个32位单精度浮点数有一个符号位、一个8位的指数和一个23位的底数。底数和指数占有的位数决定了我们可以多精确的表示一个数字。对于143.5用IEEE754可以精确表示,但是如果浮点位数过多如143.98375329,就只能被取到143.98375,因为底数只占23位。
今天的GPU已经能够表示IEEE754标准提出的单精度32位和双精度64位浮点数。IEEE单精度格式具有24位有效数字,并总共占用32位。IEEE双精度格式具有53位有效数字精度,并总共占用64位。在这里基本浮点格式是固定格式,相对应的十进制有效数字分别为7位和17位。基本浮点格式对应的C/C++类型为float和double。
但是在以前,确切说是DirectX 9.0时代伊始,GPU还是要通过一代一代的改进才能表示更精确的浮点数。在R420和NV40竞争的时代,在速度和画质选择上,ATI选择了延续FP24+SM2.0的DirectX解决方案,而NVIDIA选择了经历过NV30尝试后成熟的FP32+SM3.0的解决方案。所以我们可以通过当时的GPU硬件浮点精度来看他们表示数字的实际效果,在这里我们还是表达143.98375329:
|
浮点格式 |
结果 |
误差 |
|
NVIDIA FP16 |
143.875 |
0.10875329(7×10-2%) |
|
ATI FP24 |
143.98242 |
0.00133329(9×10-4%) |
|
NVIDIA ATI PF32 |
143.98375 |
0.00000329(2×10-6%) |
虽然在图形运算中32位单精度甚至是16位半精度已经完全足够使用,但是在面向通用计算设计的GPU中,由于需要的数据量巨大,往往只有在采用双精度甚至更高精度时才能获得可靠的结果,所以更为可靠的计算精度一直是GPU设计者不断追求的目标。但是精度提高意味着运算速度的下降,所以每一代GPU架构更新都意味着更大的寄存器和内部实现方式在高精度运算中能够获得更好的加速比。
产品:ATI Radeon HD 4850 显示芯片
整数运算能力与未来融合架构
● 整数运算能力与未来融合架构
在图形运算中,整数单元可以用来处理整数纹理过滤。纹理过滤包括两部分,一是抗失真,二是抗溢出。CPU一开始不会浮点运算,过去的CPU寄存器资源全部都是给整数单元。但是在整数运算方面,目前INT单元在通用计算中的效用不是非常明显,首先科学运算中涉及整数的场合本身就远没有浮点多,其次在这个基础上,CPU的整数一直都是很传统的保留项目。
整数单元的构成并不是GPU的性能瓶颈,但是在GPU的运算性能中,整数能力也是非常重要的环节,如果设计者忽视了这一点,将在通用计算中给GPU带来严重性能短板。比如说在穷举算法为主的密码学中几乎没有浮点密码,整数运算能力直接影响到GPU的运算效率。
OpenCL和DirectCompute两大API的推出让GPU并行计算的前途豁然开朗,此时ATI和NVIDIA在接口标准方面又重新站在了同一起跑线上。那么很显然AMD在目前GPU通用计算不能单独和NVIDIA抗衡的情况下,所选择的战略是借助于全新的API使得CPU强化整数GPU接管浮点。
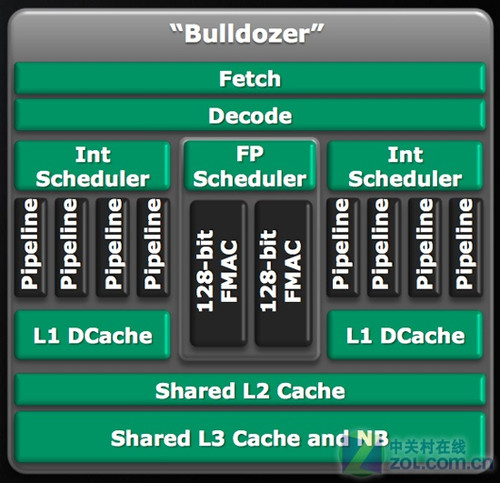
Bulldozer核心架构
AMD同时拥有CPU和GPU,而且NVIDIA和Intel都没有同时驾驭这两种差异度极高的产品线的能力,因此其未来发展规划非常值得大家思考。其下一代的高端CPU核心Bulldozer(推土机)最大的亮点就是每一颗核心拥有双倍的整数运算单元,每个单元4条并行流水线,整数和浮点为非对称设计。Bulldozer还将加入128-bit的SSE5指令集支持,达到更高的执行效率,估计还将会增加CPU寄存器数量,为单指令多数据流技术(SIMD)运算提供更多的空间。
这种设计使得浮点计算的重任开始向GPU倾斜,未来的CPU将专注整数运算能力,而如果用户需要大量的并行浮点计算,可以选择使用外置的加速卡(GPU通用计算产品)来实现。

AMD异构运算平台
在一个推土模块里面有两个独立的整数核心,每一个都拥有自己的指令、数据缓存,也就是scheduling/reordering逻辑单元。而且这两个整数单元的中的任何一个的吞吐能力都要强于Phenom II上现有的整数处理单元。Intel的Core构架无论整数或者浮点,都采用了统一的scheduler(调度)派发指令。而AMD的构架使用独立的整数和浮点scheduler。
AMD认为CPU和GPU谁也不可能取代谁,双方是互补的关系,只有CPU和GPU协同运算,各自去处理最擅长的任务,才能发挥出计算机最强的效能。从CPU漫长的发展历程来看,它会延续一路不断整合其他功能单元的道路来整合GPU,但仅限中低端产品,而且这种整合不是吞并,而是提高CPU的浮点运算性能;GPU会取代CPU进行浮点运算,但它仍然需要CPU来运行操作系统并控制整个计算机。
实际上自从2006年收购ATI以后,AMD便开始将更多精力放在一些特殊功能的电路元件上,尤其是图形处理技术。这是以前ATI的主业,ATI从R520架构开始提供的视频编码和解码技术非常出色。AMD很快在该部门中使用了所谓的“异构计算”(heterogeneous computing)技术。联系到AMD在8月16日推出全面支持OpenCL 1.1 的 ATI Stream软件开发包 (SDK) 2.2版,借助正在执行的Fusion的战略,AMD明年将首次在单芯片中实现异构计算技术。
产品:ATI Radeon HD 4850 显示芯片
GPU存储体系特点与变化
● GPU存储体系特点与变化
GPU存储体系是GPU的显著优势,当然从某一方面讲也是GPU的明显劣势。其优势是可以借助显卡PCB上焊接的GDDR3或者GDDR5显存,加上GPU内部充足的显存控制器资源获得CPU无法比拟的带宽,劣势是GPU没有足够大的Cache,并且存储体系构成与管理方式相对于CPU来说还是过于简单。
相对于串行CPU的主存储器、Cache和寄存器,图形处理器具有他们自己的存储体系结构。然而,这个存储器体系结构是针对图形加速操作设计的,适合于流式编程模型,而不是通用串行的计算。而且图形API进一步将这个存储器限制成为只能使用图形专用的图元、如顶点、纹理和显存。

CPU与GPU存储体系简析
上图演示了简单的CPU和GPU存储体系结构。GPU的存储器系统建立了现代计算机存储体系的一个分支。GPU和CPU类似,它也有自己的Cache和寄存器来加速计算中的数据访问。然而GPU自己的主存储器也有它自己的存储器空间??这意味着在程序运行之前,程序员必须明确地把数据复制写入GPU存储器。这个传输传统上是很多应用程序的一个瓶颈,但是新的PCI-Express总线标准可能使存储器在CPU和GPU之间共享数据在不远的未来变得更为可行。
具体到显存带宽方面,当前桌面级顶级产品3通道DDR3-1333的峰值是32GB/s,实测中由于诸多因素带宽在20GB/s上下浮动。HD 5870 1024MB使用了8bit预取位带宽超高的GDDR5显存,内存总线数据传输率为150GB/s的总线带宽。而主流GPU普遍拥有40-60 GB/s显存带宽。存储器的超高带宽让巨大的浮点运算能力得以稳定吞吐,也为数据密集型任务的高效运行提供了保障。

AMD GPU存储体系(RV870)
在Cache方面,为了适应更复杂的数据,在GPU内部加入Cache是一种有效的方式:最近使用的数据的副本可以由存储器传递到Cache中并根据替换协议不断更改。但是Cache由于对晶体管消耗较大,缓存协议难以实现,延迟难以控制,一直是GPU设计的重要障碍之一。
又如NVIDIA在G80架构中加入的Shared Memory和AMD在RV770架构加入的LDS(Local Data Share)。这个共享寄存器位于每个流处理器单元内部的所有运算单元中,它在通用计算时负责共享数据和临时挂起线程。容量足够大的共享缓存可以在运算时提高线程的挂起能力,还有很多东西比如乱序,分支等等都会受益于Cache的加入。
产品:ATI Radeon HD 4850 显示芯片
ATI GPU吞吐特性对比与分析
● ATI GPU吞吐特性对比与分析
我们知道ATI现有的R800架构是由R600架构演变而来的,而R600又可以看作是支持DirectX10的Xenos处理器,同时Xenos最大的特色是采用了统一着色器单元架构,这是当时最为先进的GPU架构,所以现在的R800架构还是充满了浓重的传统渲染流处理器色彩,这种沿用至今的SIMD单元同一时间内执行一个线程,各SIMD单元都有自己的寄存器供SIMD内的执行单元共享。
AMD从R600时代开始,其SIMD核心内的5D ALU采用VLIW技术,可以用一条指令完成对多个对数据的计算。图形Shader指令经过驱动的JIT(即时)编译器编译优化后,变成GPU能识别的机器码并被捆绑成长度数百位元的VLIW指令串包。VLIW指令包到达指令序列器后,会被动态重新安排,序列器会把不相依的指令捆绑成能够尽可能让SIMD单元并行执行的指令串,交给SIMD单元执行。
VLIW的效率依赖于指令系统和编译器的效率。如果指令并行度较高,则这种流处理器组织结构会受益。如果并行度较差,编译器必须尽可能地寻找指令中的并行性并将其并接为合适的长指令,这样5D ALU中的计算单元就会尽可能地被利用起来不至于浪费。虽然NVIDIA的1D ALU不会遇到这种问题,但是1D ALU最大的问题就是调度器和发射端包括寄存器的晶体管消耗量太严重,理论浮点吞吐量无法获得提升。

开放性通用计算接口OPEN CL
关于A卡和N卡在开放性的通用计算接口OPEN CL计算方面的性能差异,很多媒体进行过测试,但大家实际上一直在找一个合适的平台,在找一套合适的测试基准程序。目前,首款国人开发的支持GPU的OpenCL通用计算测试程序OpenCL General Purpose Computing Benchmark (简称GPC Benchmark OCL)已经公开并且升级到1.1版本。中关村在线显卡频道决定使用这款软件,对AMD和NVIDIA的架构特性做一些对比,以测试它们在哪些环境中能发挥出更好的理论性能。