超越图形界限 AMD并行计算技术全面解析(一)

正睿科技 发布时间:2010-08-25 16:23:54 浏览数:9969
全文导读与内容简介
● 全文导读与内容简介
在2010年8月16日,AMD宣布推出全面支持OpenCL 1.1的ATI Stream软件开发包(SDK)2.2版,新版本的SDK为开发人员提供开发强大的新一代应用软件所需要的工具。这一版本的最大意义在于它表明了AMD在不断追求与开放性应用程序接口OpenCL的兼容,同时AMD再通过OpenCL快速提升其在业行内的影响力,毕竟借助这一标准,AMD和NVIDIA站在了统一起跑线上,OpenCL接口对于一个技术与标准的追随者来说是千载难逢的机会。
作为全世界成立较早和目前仍然具备绝对影响力的图形芯片生产厂商,ATI一直在探索图形芯片发展的方向,并在这25年发展历程中长期领跑GPU性能增长。自从统一渲染架构提出以来,ATI一直在寻求对这款架构的完善,我们看到继Xenos之后的在PC市场ATI设计了R600到R800一系列性耗比和性价比广受好评的架构。

全面支持OpenCL 1.1的ATI Stream软件开发包(SDK)2.2版
不同厂商对于未来计算环境的考虑是有很大差异的,NVIDIA正在借助G80架构以来的特性不断加强GPU的通用性和编程易用性,其GPU内部大量单元用于逻辑控制和存储,而AMD则主要倾向于用最少的晶体管开销用于流处理器阵列的构建,用线程规模来掩盖延迟。总体来说,NVIDIA坚持的TLP(线程并行度)考验线程能力和并性能力,AMD坚持的ILP(指令并行度)则考验指令处理。
今天我们希望总结我们之前获得的大量资料,借助这篇文章对AMD并行计算技术做比较详细的特性分析。在文章的不同章节,我们将各有侧重地分析GPU并行计算的原理、发展历程、运算单元细节和目前我们能够找到的GPU通用计算实例。同时我们对Fermi架构、Fusion概念和Larrabee架构的特性做简单分析和预测,希望能让用户通过这些业界最为前瞻的产品找到未来GPU发展路径。
第一章:GPU工作原理与并行计算

我们将以21世纪视觉需求与GPU变化为开端回忆GPU从诞生以来的应用领域变革,通过GPU渲染流水线全面转向可编程浮点单元,GPU已经走向了并行应用,同时成为超级计算机不可或缺的部件。在目前备受关注的云计算领域,GPU同样可以发挥自己运算密度和并发线程数极高的特色,更多无法采购大型设备而急需计算资源的用户,将享受到GPU云计算带来的便利。
第二章:GPU结构与ATI芯片发展

我们将从R300架构开始回顾ATI GPU发展历程,同时和读者一起探讨不同结构流处理器指令细节,同时关注ATI第一代统一渲染架构Xenos对未来发展的影响。
第三章:GPU通用计算发展与细节
这一章我们参考大量基础性资料来讲解CPU和GPU内部功能单元的异同,通过这些异同和它们的适用环境,我们了解到AMD提出的CPU+GPU异构计算平台能够借助更好的编程接口获得更好的加速比。这种方式比单纯给GPU增加调度能力或者给CPU增加并行度要更为实际,易用性也会得到解决。
第四章:GPU内部的计算实现细节

这一部分我们关注CPU主要计算单元分布和职能,GPU内部通用计算代码运算过程,同时我们对浮点和整数能力做了进一步分析。这一章的亮点在GPU流处理器结构与性能分析部分,我们使用了较为专业的底层软件来对比不同架构的性能差异,对前文的分析做了数据佐证。
第五章:ATI GPU通用计算实例分析

本章我们首先分析了Open CL接口对于ATI GPU未来发展的影响,然后列举了一些普通用户能够找到并且参与计算的分布式并行计算项目。文章最后的蒙特卡洛算法、N-body仿真和基于GPU的计算机病毒特征匹配来自《GPU精粹3》实例分析,我们希望这种具有普遍意义的项目和算法能够拓展未来的GPU应用深度和广度。
| 濮元恺所写过的技术分析类文章索引(持续更新) | |
|
1、NVIDIA/ATI命运转折 GPU十年发展回顾 |
7、 显卡只能玩游戏? 10年GPU通用计算回顾 |
| 2、改变翻天覆地 最全Fermi架构解读 |
8、 通用计算对决 四代N卡激战CUDA-Z |
| 3、从裸奔到全身武装 CPU功能集成之路探秘 |
9、 浅析DirectX11技术 带给图形业界的改变 |
| 4、AMD统一渲染架构 历程回顾与评测 |
10、摩尔定律全靠它 CPU光刻技术分析 |
|
5、A/N谁占上风 14款显卡底层性能揭秘 |
11、从Folding@home项目看GPU通用计算 |
| 6、别浪费你的电脑 分布式计算在中国 | 12、Computex独家泄密 解析AMD下代GPU |
产品:ATI Mobility Radeon HD 4850 显示芯片 
前言:通过GPU见证行业变革
● 前言:通过GPU并行计算见证行业最大变革
从1999年到现在从第一个显卡GPU产生到现在只有短短十年的时间。在这短短十年当中我们已经看到了GPU的运算能力呈几何级数提升,这个世界在GPU的虚拟之下更快更真,而更重要的一点是GPU已经将它的应用范围不断拓展。
从图形领域虚拟现实的角度来说,只要有显示终端的地方就需要一颗GPU。借助于GPU可以让医学家观察到更细微的分子;借助于GPU可以让军事演习的拟真度更强;借助于GPU可以让专业工作站的效率翻倍提升;借助于GPU可以让电影的特效骗过你的眼睛。
最近几年中当我们发现GPU的硬件结构能够适应极高并行度与大量浮点吞吐的运算环境,更多的科学研究领域已经开始大量采购GPU设备应用于电脑辅助工程、油气勘探、金融安全评估等领域。至此,GPU存在的意义已远远不是为图形运算服务这么简单。

高性能并行计算已经成为国家竞争力的重要标志之一,对科学技术进步、经济社会发展、生态环境保护和国家与公共安全的作用日益显著。但是,在超级计算机的峰值突飞猛进的同时,其投资大、运行维护成本高、使用效率低等问题也日渐突出,成为制约超算能力提升的瓶颈。
以低廉的成本和现成的网络设施实现高效的GPU超级计算技术越来越受到很多企业及科研单位的关注。GPU运算今天已经在产业界占有一席之地,尤其在科学模型模拟的运算上,都需仰赖GPU执行,动辄比一般中央处理器(CPU)还快出数十倍,甚至数百倍的复杂数学模型运算。
通过Shader单元的可编程性将GPU运用于图形运算之外的应用领域,是本世纪初计算机行业最大的变革,它标志着一种可大规模生产的高性能芯片正在渗透传统CPU掌控的高性能计算领域。借助GPU这种运算单元密集的芯片,各行业可以获取性价比和性耗比更高的运算解决方案。
曾今很多无法想象和耗费巨大的科学命题如全球气候变化、人类基因组工程等等问题如今可以借助GPU的运算能力以更快更经济的途径实现。作为这场变革的见证和参与者,我同样有幸通过媒体的宣传力量,来推动更多人对于GPU参与高性能计算的认识和理解。本文将通过介绍一个在传统图形领域的霸主??AMD GPU产品在通用计算技术方面的发展与技术细节。
产品:ATI Radeon HD 4850 显示芯片
第一章:GPU工作原理与并行计算
● 第一章:GPU工作原理与并行计算
10年前我们所有人都认为显卡服务于制图、动画、游戏等电子娱乐领域,这没有错。因为GPU(Graphic Processing Unit 图形处理器)发明的目的就是为了应对繁杂的3D图像处理。GPU的工作通俗的来说就是完成3D图形的生成,将图形映射到相应的像素点上,对每个像素进行计算确定最终颜色并完成输出。但是谁都没有想到10年后的今天,GPU的内部架构和应用范围已经发生了翻天覆地的变化。
随着GPU的可编程性不断增强,可编程浮点单元已经成为GPU内部的主要运算力量,并且调用越来越方便,编程门槛不断降低。GPU的应用能力已经远远超出了图形渲染任务,利用GPU完成通用计算的研究逐渐活跃起来,将GPU用于图形渲染以外领域的计算成为GPGPU(General Purpose computing on graphics processing units,基于GPU的通用计算)。
以前的服务器或者超级计算机都要拆除显卡这个多余的单元以减少发热和功耗,但是GPU通用计算时代的来临将板载GPU的显卡变为超级计算机不可或缺的加速部件。其实首款专门作流处理/并行计算的GPU产品并不是现在炒的火热的NVIDIA的Tesla产品,而是ATI的Fire Stream产品。早在2006年,ATI就发布了基于R580核心的流处理加速卡,48个像素渲染单元成为流处理器的雏形。
R580核心相对于它之前的R520核心最明显的差异就是使用了20%的晶体管增量换来了200%的浮点吞吐量提升,这在当时绝对是一种创举。这种思路的提出是为了适应当时游戏编程环境越来越倚重渲染单元(Pixel Shader)运算,而这种思路的结果除了让ATI在DirectX 9.0时代末期赢得了性能王座之外,还造就了历史上第一款用于图形计算之外的Fire Stream产品。
高性能并行计算发展迅速
上世纪60年代初期,大型主机(Mainframe)的问世标志着并行计算机诞生,随后我们看到计算机体系越来越成熟。高性能计算机甚至体现了一个国家在高科技领域的发言权,其经济发展速度和结构也与高性能计算机的计算能力息息相关。同时随着个人电脑计算能力的增长缓慢和计算需求的提升,云计算似乎成为目前炙手可热的话题。
放眼整个高性能并行计算领域,业界正在为X86架构CPU性能提升缓慢而感到担忧,特别是目前X86架构频率提升不断遇到障碍,并行度受制于传统CISC架构难以获得飞跃。超级计算机只能通过堆砌节点数量还换取性能提升吗?有没有一种性价比性耗比更高的解决方案?也许让每台PC机内置的GPU来处理这些并行数据再合适不过了。
在本章我们将分析GPU工作原理和历史沿革,并告诉读者这种芯片结构为什么能够适应大规模并行计算。同时我们在本章对目前业界所关注的高性能并行计算和云计算也做了简短分析。
产品:ATI Mobility Radeon HD 4850 显示芯片
21世纪视觉需求与GPU变化
● 21世纪视觉需求与GPU变化
2009年10月30日,我国首套GPU超级计算机“天河一号”由国防科学技术大学研制成功。这套计算机采用了创新的CPU+GPU异构计算设计,不但理论计算性能得到大幅提升,而且达到了很高的能效比。天河一号采用6144个Intel通用多核处理器和5120个AMD图形加速处理器,实测性能排列2009年6月TOP500第四位,峰值性能列第三位。

我国首套GPU超级计算机“天河一号”
在此前的一年,全世界范围内已经出现了越来越多的搭载GPU的超级计算机,而随后的一年中,中国再次使用NVIDIA Tesla产品打造了全世界排名第二的超级计算机系统。之所以GPU频繁登陆大规模并行计算领域,是因为21世纪人类所面临的科研课题已经无法用传统的CPU架构来负责运算。
放下之前讨论的超级计算机回到图形领域,我们会发现21世纪视觉需求同样对硬件发展提出了近乎可不能完成的任务。无论是使用了当时全新游戏引擎的《毁灭战士3》(Doom 3)还是首次使用延迟渲染技术的《彩虹6号:维加斯》,直到DirectX 10时代测试显卡不可缺少的项目《孤岛危机》,都在给游戏玩家带来巨大震撼的同时考验着PC硬件的承受能力。

DirectX 10时代测试显卡不可缺少的项目《孤岛危机》
实际上从1995年id software创作出第一款震惊世界的3D游戏《毁灭战士》开始,个人电脑3D游戏之路开始变得无限宽阔。甚至有一句话一直回荡在所有资深游戏玩家耳边“上帝花了6天创造了这个世界,id software和它的创始人、引擎师约翰•卡马克(John Carmark),则用6款游戏创造了个人电脑的3D世界。”

史诗电影《圆明园》
除了PC游戏应用对GPU发展的牵引力之外,专业渲染领域同样对强大的GPU运算能力充满渴求。我们在2006年看到了使用当时最先进GPU技术来制作的史诗电影《圆明园》,这部电影大规模使用电脑场景仿真动画技术,重现圆明园的瑰丽与辉煌。在国防军工方面,GPU也得到了广泛应用,最先进的战斗机上已经安装了专业GPU用于绘制目标标示和数据显示。大型军事视景仿真系统已经将一款高端的GPU芯片作为标配硬件。

GPU运算单元爆炸式增长
GPU为了能够满足人类“贪婪”的视觉需求,内置了大量的运算单元,它们从负责三角形生成到顶点与像素的处理,特别是着色引擎为了更快更多实现图形渲染而迅速扩张,使得GPU的晶体管集成度以超越CPU摩尔定律3倍的速度发展,同一时期GPU的浮点吞吐速度也达到了CPU的十倍左右。
产品:ATI Radeon HD 4850 显示芯片
从山峰渲染了解GPU图形流水线
● 从山峰渲染了解GPU图形流水线
在这一部分,笔者将和大多数初识GPU的爱好者一道探寻GPU的渲染步骤,我们使用一座山峰的渲染历程来帮助大家简单理解GPU图形流水线的工作原理。简单的说:GPU主要完成对3D图形的处理??图形的生成渲染。

从山峰渲染看GPU图形流水线
1、顶点生成
图形学API(应用程序接口)用最初级的图元(点、线、三角形)来表示物体表面。每个顶点除了(x,y,z)三维坐标属性外还有应用程序自定义属性,例如位置、颜色、标准向量等。结合到我们看到的这座山峰,首先GPU从显存中读取描述山峰3D外观的顶点数据。
2、顶点处理
这阶段GPU读取描述3D图形外观的顶点数据并根据顶点数据确定3D图形的形状及位置关系,建立起3D图形的骨架。在支持DX8和DX9规格的GPU中,这些工作由硬件实现的Vertex Shader(顶点着色器)完成。这个阶段中GPU生成一批反映山峰三角形场景位置与方向的顶点。
3、光栅化计算
显示器实际显示的图像是由像素组成的,我们需要将上面生成的图形上的点和线通过一定的算法转换到相应的像素点。把一个矢量图形转换为一系列像素点的过程就称为光栅化。例如,一条数学表示的斜线段,最终被转化成阶梯状的连续像素点。
在屏幕空间内生成山峰顶点之后,这些顶点被分为三角形图元,GPU内的固定单元会对这些山峰图元做光栅化过程,相应的片元集合也就随之产生。

GPU内部渲染流水线
4、纹理帖图
顶点单元生成的多边形只构成了3D物体的轮廓,而纹理映射(texture mapping)工作完成对多变形表面的帖图,通俗的说,就是将多边形的表面贴上相应的图片,从而生成“真实”的图形。TMU(Texture mapping unit)即是用来完成此项工作。
5、像素处理
这个阶段(在对每个像素进行光栅化处理期间)GPU完成对像素的计算和处理,从而确定每个像素的最终属性。在支持DX8和DX9规格的GPU中,这些工作由硬件实现的Pixel Shader(像素着色器)完成。
像素操作用每个片元的屏幕坐标来计算该片元对最终生成图像上的像素的影响程度。在这个阶段Pixel Shader(像素着色器)从显存中读取纹理数据对山峰片元上色并渲染。
6、最终输出:
由ROP(光栅化引擎)最终完成像素的输出,1帧渲染完毕后,被送到显存帧缓冲区。AA即多重采样,对ROP性能和图形卡带宽有相当的压力。而各项异性过滤则对TMU带来更多的负担。
这个阶段由ROP单元完成所有山峰像素到帧缓冲区的输出,帧缓冲区内的数据,经过D/A转换输出到显示器之后,我们就可以看到绘制完成的山峰图像。
产品:ATI Radeon HD 4850 显示芯片
● CPU与GPU的设计方向决定运算能力
CPU与GPU的设计方向决定运算能力
近30年来,由Intel、IBM、SUN、AMD和富士通生产的通用CPU虽然有了很大发展,但性能提高速度却已经不能与上世纪八十年代末九十年代初相比。单线程处理性能在很大程度上受到了限制。这些限制一方面来自于通用计算程序中过低的指令级并行;另一方面来自于“功率墙(Power Wall)”??集成电路的功率消耗的物理限制。
而GPU的用途已经远远超出运行游戏,我们买到的显卡其实是一块高性能加速器。特别是现在NVIDIA和AMD的显卡产品都体现出了极高的浮点运算能力,双精度浮点运算中的衰减也越来越小。
举例说,在Folding@home项目中,一款中端显卡一天24小时可以计算10个左右的大分子蛋白质折叠,而一款酷睿2双核E7200处理器的一个核心在24小时内完成一个小分子包运算任务都非常困难。CPU和GPU在高密度多线程浮点运算中体现出的性耗比差异,相信大家已经非常清楚。在这一节,我们将着重分析GPU相对于CPU的架构优势。
CPU和GPU架构差异很大,CPU功能模块很多,能适应复杂运算环境;GPU构成则相对简单,目前流处理器和显存控制器占据了绝大部分晶体管。CPU中大部分晶体管主要用于构建控制电路(比如分支预测等)和Cache,只有少部分的晶体管来完成实际的运算工作。

CPU和GPU逻辑架构对比
而GPU的控制相对简单,而且对Cache的需求小,所以大部分晶体管可以组成各类专用电路、多条流水线,使得GPU的计算速度有了突破性的飞跃,拥有了惊人的处理浮点运算的能力。现在CPU的技术进步正在慢于摩尔定律,而GPU(视频卡上的图形处理器)的运行速度已超过摩尔定律,每6个月其性能加倍。
CPU的架构是有利于X86指令集的串行架构,CPU从设计思路上适合尽可能快的完成一个任务;对于GPU来说,它的任务是在屏幕上合成显示数百万个像素的图像??也就是同时拥有几百万个任务需要并行处理,因此GPU被设计成可并行处理很多任务,而不是像CPU那样完成单任务。

CPU内部架构
当今CPU仅前端部分就非常复杂,指令解码、分支预测等部分消耗晶体管数量巨大。CPU的设计目标是不仅要有很高的吞吐量,还要有良好的应用环境兼容性,CPU所要面对的应用面远远超过了GPU。CPU是设计用来处理通用任务的处理、加工、运算以及系统核心控制等等的。CPU中包含的最基本部件有算术逻辑单元和控制单元,CPU微架构是为高效率处理数据相关性不大的计算类、复杂繁琐的非计算类的等工作而优化的,目的是在处理日常繁复的任务中应付自如。
GPU设计的宗旨是实现图形加速,现在最主要的是实现3D图形加速,因此它的设计基本上是为3D图形加速的相关运算来优化的,如z-buffering消隐,纹理映射(texture mapping),图形的坐标位置变换与光照计算(transforming & lighting)等等。这类计算的对象都是针对大量平行数据的,运算的数据量大。但是GPU面对的数据类型比较单一,单精度浮点占到其处理数据的绝大多数,直到GTX200和HD 4800系列显卡才对双精度运算提供了支持。
产品:ATI Radeon HD 4850 显示芯片
GPU并行编程为何加速发展
● GPU并行编程为何加速发展
回到我们刚开始讨论的地球科学、医学研究与金融建模那些计算问题,可能有很多读者会问到“为什么要花这么大力气将传统CPU上运行的程序移植到GPU环境中运行?”答案其实很简单??追求更高的性价比和性耗比。

GPU能够明显加速算术密集型并行计算任务
虽然GPU并不适用于所有问题的求解,但是我们发现那些对运算力量耗费巨大的科学命题都具备天然的“算术密集型”特色。这类程序在运行时拥有极高的运算密度、并发线程数量和频繁地存储器访问,无论是在音频处理、视觉仿真还是到分子动力学模拟和金融风险评估领域都有大量涉及。这种问题如果能够顺利迁移到GPU为主的运算环境中,将为我们带来更高效的解决方案。

浮点能力首次超越1TFLOPS的ASCI Red超级计算机
在1996年,美国Sia国家实验室研发了超级计算机“ASCI Red”,浮点运算性能首次突破1TFlops,但它需要非常多的节点和耗电。它是一套基于mesh网状结构(38 X 32 X 2)的MIMD大规模并行机(MIMD massively parallel machine),起初包含7264个计算节点、1212GB分布式内存和12.5TB磁盘存储容量。
该机器的原型使用的是英特尔的Pentium Pro处理器,每个处理器的时钟频率达到200MHz,后来才升级到Pentium II OverDrive处理器。升级后的系统拥有9632个处理器,每个处理器的主频为333MHz。ASCI Red超级计算机由104个机柜组成,占地面积达到了230平方米。

廉价的1TFLOPS解决方案??Radeon HD4000系列产品
时间一晃而过到2008年,ATI发布了统一渲染架构下的第二代PC领域GPU产品??Radeon HD4000系列产品,其中定位在中高端市场的Radeon HD4850显卡在当时使用了800个频率达到625MHz的流处理器,仅用110W的耗电带来了1TFlops的运算能力。这时人类获取1TFlops的经济支出仅为199美元。

一款HD5870相当于177台深蓝超级计算机节点
仅仅一年之后,ATI再次发力优化统一渲染架构,发布了Radeon HD5000系列产品,其中高端产品HD5870已经集成了2.7 TFlops运算能力。这颗GPU的问世标志着ATI已经成熟掌握了40nm制程工作、DirectX 11应用程序接口和吞吐带宽极高的DDR5显存。同时这颗GPU的运算能力相当于177台深蓝超级计算机节点。
传统意义上的GPU不善于运行分支代码,但是ATI和NVIDIA经过长期改进其内部架构已经使得GPU可以较为高效地运行分支、循环等复杂代码。同时因为GPU属于并行机范畴,相同的运算可以应用到每个数据元素的时候,它们可以达到最好的性能。在CPU编程环境中,写出每个输入数据元素有不同数量的输入的程序很容易,但在GPU这种并行机上还是有不少麻烦。
通用的数据结构正是GPU编程的最大困难之一。CPU程序员经常使用的数据结构如列表和树在GPU身上并不容易实现。GPU目前还不允许任意存储器访问,而且GPU运算单元的设计为主要操作是在表现位置和颜色的四维向量上。
不过这些并不能阻挡GPU编程的加速发展,因为GPU不是真的为通用计算而设计的,需要一些努力才能让GPU高速地服务通用计算程序。这些努力前些年是程序员而单独实现的,而随着ATI和NVIDIA开始看到高性能计算市场的硬件需求,我们看到无论是Fermi架构添加全能二级缓存和统一定址还是RV870架构不断优化LDS并放大并发线程数,这些都是GPU自身硬件体系为了适应未来的运算环境而做出的变革。
产品:ATI Radeon HD 4850 显示芯片
GPU并行计算已成未来趋势
● GPU并行计算已成未来趋势
无数游戏玩家疯狂的购买力已经使得GPU这种芯片的价格下跌到只要花一百美元就能买到一颗性能级GPU产品,那为什么不大面积部署这种产品,来降低超级计算机的价格呢?从2006年的第一款Fire Stream产品开始,业内人士已经发现了GPU在处理大并行度程序时所表现出的超常性能。
在传统的GPU种,Shader单元从出现(2001年DirectX 8发布标志着Shader单元出现)到运算能力迅速提升(2007年Geforce 8800GTX发布,通用计算影响力显著扩大)经过了很长时间。在这段时间里,显卡对于高端大规模并行运算是毫无价值的,即使有少量业界先行者开始了思考和研究,也无法形成对整个产业的影响力。

GPU开始应用于超级计算机
这个阶段在超级计算机与集群中,往往要拆除“多余的”显卡以节能功耗,而自从AMD公司的Stream架构NVIDIA公司的CUDA架构奠定了GPU通用计算地位之后,现在的设计开始逐渐采用大量GPU来获得更加廉价和绿色的计算能力。CUDA的强大性能引发了一场通用计算革命,这场革命将极大地改变计算机的面貌。
但是随着GPU的可编程性不断增强,GPU的应用能力已经远远超出了图形渲染任务,利用GPU完成通用计算的研究逐渐活跃起来,将GPU用于图形渲染以外领域的计算成为GPGPU(General Purpose computing on graphics processing units,基于GPU的通用计算)。
而与此同时CPU则遇到了一些障碍,CPU为了追求通用性,将其中大部分晶体管主要用于构建控制电路(比如分支预测等)和Cache,只有少部分的晶体管来完成实际的运算工作。在CPU上增加并行度已经变得越来越困难,虽然HTT超线程技术在Intel的推广下得以应用在自家的高端CPU中,但是目前单颗CPU所拥有的最大线程数还只是12个。
我们已经习惯了计算机核心性能的不断提升,而且似乎认为这是理所当然的事。因为传统芯片的性能提升可以依赖芯片制造工艺的进步。这种进步我们通常用摩尔定律来概括。1965年Intel的创始人戈登•摩尔(Gordon Moore)通过长期的对比研究后发现:CPU中的部件(我们现在所说的晶体管)在不断增加,其价格也在不断下降。“随着单位成本的降低以及单个集成电路集成的晶体管数量的增加;到1975年,从经济学来分析,单个集成电路应该集成65000个晶体管。”Intel此后几年的发展都被摩尔提前算在了纸上,使人们大为惊奇,“摩尔定律”也名声大振。为了让人们更直观地了解摩尔定律,摩尔及其同事总结出一句极为精练的公式 “集成电路所包含的晶体管每18个月就会翻一番”。

Intel定义的摩尔定律与晶体管数量增长
将摩尔定律简单应用在芯片集成度的增长方面,我们可以得出这在今天意味着:每年单芯片中可以大约多放置50%的元件。这种技术表面上为我们的芯片发展铺平了道路,虽然大多数趋势是向好的。比如说20年前芯片设计者刚刚开始把浮点运算单元FPU集成到CPU核心,但是20年后这个单元制占用1平方毫米不到的空间,而且同一个核心上可以放置上百个浮点运算单元。
但是这种性能提升并不是无止境的,而且这些技术发展最重要的后果是它们之间的区别。当某一指标变动速度和其他指标变动速率不同时,我们就需要重新考虑在芯片和系统设计背后的假设。换而言之目前CPU已经遇到了非常严重的计算与通信障碍、存储器延迟与带宽障碍和发热与功耗。而GPU在这3个方面表现显然要比CPU更为出色,在后文我们将详细分析GPU在这诸多方面的特性。
产品:ATI Radeon HD 4850 显示芯片
初识高性能并行计算
● 初识高性能并行计算
并行计算是指同时对多个任务或多条指令、或对多个数据项进行处理。完成此项处理的计算机系统称为并行计算机系统,它是将多个处理器(可以几个、几十个、几千个、几万个等)通过网络连接以一定的方式有序地组织起来(一定的连接方式涉及网络的互联拓扑、通信协议等,而有序的组织则涉及操作系统、中间件软件等)。

简单认识并行计算编程
并行计算的主要目的:一是为了提供比传统计算机快的计算速度;二是解决传统计算机无法解决的问题。同时科学与工程计算对并行计算的需求是十分广泛的,但所有的应用可概括为三个方面:
1、计算密集型(Compute-Intensive)
这一类型的应用问题主要集中在大型科学工程计算与数值模拟(气象预报、地球物理勘探等)。
这一类型的应用问题主要集中在大型科学工程计算与数值模拟(气象预报、地球物理勘探等)。
2、数据密集型 (Data-Intensive)
Internet的发展,为我们提供了大量的数据资源,但有效地利用这些资源,需要进行大量地处理,且对计算机的要求也相当高,这些应用包括数字图书馆、数据仓库、数据挖掘、计算可视化。
Internet的发展,为我们提供了大量的数据资源,但有效地利用这些资源,需要进行大量地处理,且对计算机的要求也相当高,这些应用包括数字图书馆、数据仓库、数据挖掘、计算可视化。
3、网络密集型 (Network-Intensive)
通过网络进行远距离信息交互,来完成用传统方法不同的一些应用问题。如协同工作、遥控与远程医疗诊断等。
通过网络进行远距离信息交互,来完成用传统方法不同的一些应用问题。如协同工作、遥控与远程医疗诊断等。

并行度极高的RV870拥有1600个流处理器
GPU所擅长应对的并行计算问题,正是我们之前提到的计算密集型(Compute-Intensive)问题。因为GPU内部大量充斥着ALU运算单元阵列,这种单元应对并行度高运算密度大的问题比CPU获取的加速比要高很多倍。

理解串行运算与并行运算
通过上图我们可以较为容易地理解串行运算和并行运算之间的关系。传统的串行编写软件具备以下几个特点:要运行在一个单一的具有单一中央处理器(CPU)的计算机上;一个问题分解成一系列离散的指令;指令必须一个接着一个执行;只有一条指令可以在任何时刻执行。
而并行计算则改进了很多重要细节:要使用多个处理器运行;一个问题可以分解成可同时解决的离散指令;每个部分进一步细分为一系列指示;每个部分的问题可以同时在不同处理器上执行。
产品:ATI Radeon HD 4850 显示芯片
高性能并行计算发展历程
● 高性能并行计算发展历程
计算机的起源可以追溯到欧洲文艺复兴时期。16-17 世纪的思想解放和社会大变革,大大促进了自然科学技术的发展,其中制造一台能帮助人进行计算的机器,就是最耀眼的思想火花之一。
1614年,苏格兰人John Napier 发表了关于可以计算四则运算和方根运算的精巧装置的论文。1642年,法国数学家Pascal 发明能进行八位计算的计算尺。1848 年,英国数学家George Boole创立二进制代数学。1880 年美国普查人工用了7年的时间进行统计,而1890年,Herman Hollerith用穿孔卡片存储数据,并设计了机器,仅仅用了6个周就得出了准确的数据(62,622,250人)。1896 年,Herman Hollerith 创办了IBM公司的前身。这些" 计算机",都是基于机械运行方式,还没有计算机的灵魂:逻辑运算。而在这之后,随着电子技术的飞速发展,计算机开始了质的转变。
1949年,科学杂志大胆预测“未来的计算机不会超过1.5 吨。”真空管时代的计算机尽管已经步入了现代计算机的范畴,但其体积之大、能耗之高、故障之多、价格之贵大大制约了它的普及应用。直到1947 年,Bell实验室的William B. Shockley、John Bardeen和Walter H. Brattain. 发明了晶体管,电子计算机才找到了腾飞的起点,开辟了电子时代新纪元。
40年代开始的现代计算机发展历程可以分为两个明显的发展时代:串行计算时代、并行计算时代。
并行计算机是由一组处理单元组成的,这组处理单元通过相互之间的通信与协作,以更快的速度共同完成一项大规模的计算任务。因此,并行计算机的两个最主要的组成部分是计算节点和节点间的通信与协作机制。并行计算机体系结构的发展也主要体现在计算节点性能的提高以及节点间通信技术的改进两方面。

IBM360大型主机(Mainframe)
60年代初期,由于晶体管以及磁芯存储器的出现,处理单元变得越来越小,存储器也更加小巧和廉价。这些技术发展的结果导致了并行计算机的出现,这一时期的并行计算机多是规模不大的共享存储多处理器系统,即所谓大型主机(Mainframe)。IBM360是这一时期的典型代表。
1976年CRAY-1 问世以后,向量计算机从此牢牢地控制着整个高性能计算机市场15 年。CRAY-1 对所使用的逻辑电路进行了精心的设计,采用了我们如今称为RISC 的精简指令集,还引入了向量寄存器,以完成向量运算。
80年代末到90年代初,共享存储器方式的大规模并行计算机又获得了新的发展。IBM将大量早期RISC微处理器通过蝶形互连网络连结起来。人们开始考虑如何才能在实现共享存储器缓存一致的同时,使系统具有一定的可扩展性(Scalability)。90年代初期,斯坦福大学提出了DASH 计划,它通过维护一个保存有每一缓存块位置信息的目录结构来实现分布式共享存储器的缓存一致性。后来,IEEE 在此基础上提出了缓存一致性协议的标准。
一个基于NUMA架构的SMP服务器
90年代以来,主要的几种体系结构开始走向融合。属于数据并行类型的CM-5除大量采用商品化的微处理器以外,也允许用户层的程序传递一些简单的消息;CRAY T3D是一台NUMA结构的共享存储型并行计算机,但是它也提供了全局同步机制、消息队列机制,并采取了一些减少消息传递延迟的技术。
今天,越来越多的并行计算机系统采用商品化的微处理器加上商品化的互连网络构造,这种分布存储的并行计算机系统称为机群。国内几乎所有的高性能计算机厂商都生产这种具有极高性能价格比的高性能计算机,并行计算机就进入了一个新的时代,并行计算的应用达到了前所未有的广度和深度。
产品:ATI Radeon HD 4850 显示芯片
高性能并行计算单元分类
● 高性能并行计算单元分类
受到工艺、材料导致的功耗和发热等物理限制,处理器的频率不会在短时间内有飞跃式的提高,因此采用各种并行方式来提高运算能力已经成为业界共识。在现代的CPU中我们看到设计者广泛使用了超标量、超流水线、超长指令字,SIMD、超线程、分支预测等手段挖掘程序内的指令集并行,并且主流的CPU也有多个处理核心。而GPU与生俱来就是一种“众核”并行处理器,在处理单元的数量上还要远远超过CPU。
实际上我们之前所讲到的并行是一个非常笼统的概念,并行根据层次不同可以分为几种方式,我们可以将各个层级的并行在这里简单分析:
最为微观的是单核指令级并行(ILP),它可以让单个处理器的执行单元同时处理多条指令:向上一个层级是多核并行,它的实现方式是在一个芯片上放置多个物理核心,实现线程级别并行(TLP);再向上则是多处理器并行(Mutil-Processor),它的实现方法是在一块主板上安装多个处理器,以实现线程和进程级别并行;最后可以借助网络实现大规模集群或分布式并行(Cluster Distributed Parallel),这种环境中每个节点就是一台计算机,可以实现更大规模的并行计算。
Flynn(1966年)分类法是根据系统的指令流和数据流对计算机系统进行分类的一种方法。Flynn分类法通过鉴定数据流和指令流来区分不同类型的计算机系统。其中以下几种就是Flyuu分类法得出的计算机结构:
SISD单指令流单数据流 (Single Instruction stream Single Data stream)
SIMD单指令流多数据流 (Single Instruction stream Multiple Data stream)
MISD 多指令流单数据流(Multiple Instruction stream Single Data stream)
MIMD多指令流多数据流 (Multiple Instruction stream Multiple Data stream)
SIMD单指令流多数据流 (Single Instruction stream Multiple Data stream)
MISD 多指令流单数据流(Multiple Instruction stream Single Data stream)
MIMD多指令流多数据流 (Multiple Instruction stream Multiple Data stream)

Flyuu分类法得出的计算机结构
SISD:传统的单处理机系统。由程序生成的一个单指令流,在任意时刻处理单独的数据项。

SISD结构简析

SISD结构计算机代表
SIMD:如:阵列处理机系统(Processor Arrays)。由一个控制器负责从存储器中取出指令并将这些指令发送给各个处理器,每个处理器同步执行相同的指令,但操作不同的数据。

SIMD结构简析

SIMD结构计算机代表
MISD:相当于在指令一级并行,而在被操作的数据级串行的情况,实际上这种模型是不能实现的。

MISD结构简析
MIMD:当今绝大多数并行计算机都属于这一类。每个处理器拥有一个单独的程序,每个程序为每一个处理器生成一个指令流,每条指令对不同的数据进行操作。

MIMD结构简析

MIMD结构计算机代表
Flynn分类法实际上并不能对所有计算机进行分类,如流水线向量处理机就难于按Flynn分类法简单地归为上述四类之一。并行计算机系统除少量专用的SIMD系统外,绝大部分为MIMD系统。
产品:ATI Radeon HD 4850 显示芯片
初识基于GPU系统的云计算
● 初识基于GPU系统的云计算
近年来“云计算”这个名词的出现频率越来越高,就连我们日常应用中再也普通不过的输入法居然也有云计算版本,不由得让人感慨,互联网发展速度实在太快,云计算已经开始走进千家万户了。
云计算概念最初是由Google提出的,这是一个美丽的网络应用模式。狭义云计算是指IT基础设施的交付和使用模式,指通过网络以按需、易扩展的方式获得所需的资源;广义云计算是指服务的交付和使用模式,指通过网络以按需、易扩展的方式获得所需的服务。
我们可以将云计算(Cloud computing)看作是一种新兴的共享基础架构的方法,可以将巨大的系统池连接在一起以提供各种IT服务。很多因素推动了对这类环境的需求,其中包括连接设备、实时数据流、SOA的采用以及搜索、开放协作、社会网络和移动商务等这样的Web2.0应用的急剧增长。
我们可以接触到的云计算服务
当我们的系统资源不够时,我们可以通过云计算服务商提供的云计算能力来储存数据;当我们没有安装Office类办公软件的时候,我们可以通过Google提供的网络文档编辑文字和图表;当我们遇到自己的电脑无法解决的计算难题时,我们也可以通过云计算的方式让强大的超级计算机或者计算机集群来解决你的问题。
那什么是基于GPU的云计算呢?这个定义其实很简单,此前的种种云计算,都是通过网络传输CPU的运算能力,为客户端返回计算结果或者文件;而GPU云计算则偏重于图形渲染运算或大规模并行计算,为客户端传送逼真的2D图形或3D图像。
当客户端(网络终端)发出请求后,服务器按照要求渲染出高品质的图像发送回来、或者将3D动作以在线流媒体的形式传输回来。对于客户端来说虽然不是实时渲染,但只要网速足够,那就能保证最终的显示效果。

基于ATI Stream硬件的云计算环境
3D云计算最大的好处就是对客户端系统配置的要求大大降低,图形性能很差的老电脑或上网本都可以使用,带有Wifi或3G网络的手机可以随时随地的进行各种3D应用甚至玩游戏,这在以往是不敢想象的。
通过上图我们可以看到,用户的计算机上也许没有强大的CPU和强大的GPU,所以在运行一些大型程序时受到诸多限制。而通过基于ATI Stream硬件的云计算,用户可以将这些计算任务交由远程的ATI Stream硬件集群完成,自身硬件性能的限制可以通过云计算来打破。
和传统的纯粹依靠CPU来进行图像动画渲染计算的服务器相比,Tesla RS GPU系统性能可以高出几十倍,因此能够实时渲染好照片和动画,并把结果传送到终端,而这正是云服务或互联网服务的基本要求,而以往你可能要等上几个小时甚至几天的时间。基于GPU的3D云计算则依靠集群服务器实现实时光线追踪渲染,让普通用户也能感受到顶尖图形技术的魅力。
基于GPU的云计算的应用领域相当广,不同的应用方式对于服务器的要求也不尽相同,简单而言客户端用户数量越多,需要更多的GPU运算资源。封闭的企业级应用反而要求不是很高,针对公众开放式的在线商店或者产品演示、网络游戏等要求最高,当然也将会产生巨大的经济效益。随着云计算的普及,越来越多的中小企业将会受益于这种计算模式,这些企业或工作室不用购买费用高昂的硬件来维持运行,只需租用或免费使用云计算资源,即可享受到远程云端提供的庞大运算能力。
产品:ATI Radeon HD 4850 显示芯片
第二章:GPU结构与ATI产品发展
● 第二章:GPU结构与ATI产品发展
3D计算机图形基本图元是投射空间中的3D顶点,表示为一个四元组(x,y,z,w)的向量,四维的颜色存储为四元组(red,green,blue,alpha)的向量(通常缩写为R,G,B,A),其中Alpha一般表示透明的百分比。统的GPU基于SIMD的架构。
SIMD即Single Instruction Multiple Data,单指令多数据。这种架构天生是为了应对顶点与像素四元组数据而设计的。随后像素着色器还是延续SIMD结构,而顶点单元设计成MIMD组织形式,这是因为顶点单元的操作相对简单,以VS为基础试做MIMD的结构,不论操控还是吞吐都会比较好调整,而且能够得出很好的实验数据。这种分歧,奠定了AMD和NVIDIA两家公司未来的GPU架构主要区别。
作为全世界成立较早和目前仍然具备绝对影响力的图形芯片生产厂商,ATI一直在探索图形芯片发展的方向,并在这25年发展历程中长期领跑GPU性能增长。ATI在1985年使用ASIC技术开发出了第一款图形芯片和图形卡,并在1996年发布了业内第一款3D图形芯片。2000年4月ATI发布了Radeon图形芯片,这是当时世界上最强的图形处理器,Radeon标志着ATI进入高端游戏和3D工作站市场。
2002年ATI发布了让竞争对手无法想象的Radeon 9700芯片,这是R300架构的高端旗舰,也是当时所有高端玩家和专业图形工作站梦寐以求的GPU产品。2003年ATI为微软推出的游戏主机XBOX开发业界尖端的图形单元Xenos,并影响了此后几年间的图形编程环境。这款芯片另一层意义在于它打开了ATI统一渲染架构道路,也为后来几年的产品发展变化打下了坚实基础。
2006年夏季,ATI与AMD做了一次“门当户对”的联姻,此后ATI品牌仍然存在并继续和NVIDIA在图形芯片市场上抗衡。2009年9月AMD发布了业内首款基于DirectX 11的Radeon HD5870显卡,同时将ATI Radeon品牌再次带上性能顶峰。这颗代号RV870的芯片还有一个重大的意义在于它将ATI统一渲染架构做到了最难以掌握的平衡。

合并后的AMD和ATI能够带来新的契机
自从统一渲染架构提出以来,ATI一直在寻求对这款架构的完善,我们看到继Xenos之后的在PC市场ATI设计了Radeon HD2900XT,它能够支持DirectX10标准,拥有当时规模最大的流处理器阵列和显存控制器。Radeon HD3870则代表了工艺和架构的完美妥协,它为用户提供了性价比较高的选择。
随后发布的Radeon HD4870大幅度改进了芯片架构,面向通用计算增加了LDS单元,设计了更为复杂的存储体系,中高端单芯片突破1TFLOPS是它的典型特征,这一浮点吞吐量背后的支撑是它相对于上一代产品2.5倍的流处理器ALU数量提升。直到我们现在使用的ATI高端产品Radeon HD5870则将ATI统一渲染架构浮点吞吐推向极致,在优化存储体系和运算单元的同时,获得了业内公认的更高性耗比。
未来ATI图形芯片架构将会呈现出如何的发展趋势?SIMD结构流处理器的优势是否值得继续保留?或许ATI在嫁给AMD之后做出的抉择远比我们想象的要复杂很多,这种抉择已经不是为了产品更适应市场,而是为了AMD今后对自身的定位和发展方向。
在这一部分我们将从Xenos芯片的设计思路来展开我们对统一渲染架构的探寻和预测。当然不要忘记AMD未来还有一款神奇的产品即将出现在我们的视野,那就是Fusion融合架构相关产品,我们相信最快速度的融合能够提升产品的效能和竞争力,而更深层次的融合将带来更大的想象空间。
产品:ATI Radeon HD 4850 显示芯片
统一着色器架构释放GPU运算能力
● 统一着色器架构再次释放GPU运算能力
Shader Model 在诞生之初就为我们提供了Pixel Shader(顶点着色器)和Vertex Shader(像素着色器)两种具体的硬件逻辑,它们是互相分置彼此不干涉的。但是在长期的发展过程中,NVIDIA和ATI的工程师都认为,要达到最佳的性能和电力使用效率,还是必须使用统一着色器架构,否则在很多情况下Pixel Shader计算压力很轻造成大量Pixel Shader单元闲置,Vertex Shader资源有限但遇到大量三角形时会忙不过来。也就是说不再区分Pixel Shader和Vertex Shader,最终设计出来的产品可以在任何API编程模型中都不存在任何顶点/像素着色器固定比率或者数量限制。

Vertex Shader和Pixel Shader负载对比
每一帧渲染中Vertex Shader和Pixel Shader负载压力几乎没有相关性,总是在出现资源闲置和资源紧缺,所以有必要使用统一着色器架构。
在统一着色器架构的GPU中,Vertex Shader和Pixel Shader概念都将废除同时代之以ALU。ALU是个完整的图形处理体系,它既能够执行对顶点操作的指令(代替VS),又能够执行对象素操作的指令(代替PS)。GPU内部的ALU单元甚至能够根据需要随意切换调用,从而极大的提升游戏的表现。
微软XBOX 360所采用的Xenos图形处理器,第一次引入了统一着色器架构,这个着色器架构包含了3个独立的着色器矩阵,每个着色器矩阵内有16个5D向量SIMD单元,这些SIMD单元既可以执行Vertex Shader也可以执行Pixel Shader,可以称之为符合DirectX9标准的统一着色器架构。随后NVIDIA推出的GeForce 8800 GTX使用了128个标量流处理器(Stream Processor)。在通用计算方面,GeForce 8800 GTX的统一架构比Xbox 360的C1更先进、更强大,这表现在标量设计、整个US和Shader簇内的MIMD化执行。
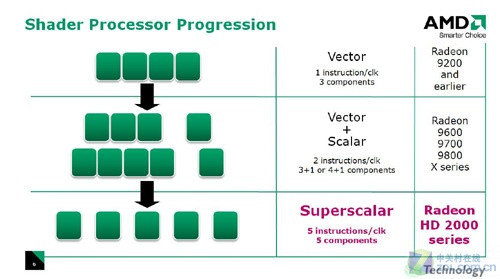
AMD历代着色器演进
在GeForce 8800 GTX之后,AMD经过数月的延迟后推出了代号R600的RADEON HD 2900XT核心,这款产品和NVIDIA的新品一样使用了统一渲染架构,不同之处在于2900XT的64个SIMD着色器内包含了5路超标量(superscalar)的运算单元(ALU),我们习惯性称其拥有320个流处理器。组织形式方面,SIMD单元采用超标量+VLIW(甚长指令)设计,虽然从数量上看规模庞大(共拥有320个ALU,8800 GTX为128个),但是执行效率在实际运算特别是通用计算中会发生不可忽视地衰减。
为方便讨论,在后文分析中,我们将更多地把着色器Shader称为流处理器Stream Processor。
产品:ATI Radeon HD 4850 显示芯片
传统GPU发展与着色器管线
● 传统GPU发展与着色器管线
根据第一章的讲解,我们了解到渲染一个复杂的三维场景,需要在一秒内处理几千万个三角形顶点和光栅化几十亿的像素。早期的3D游戏,显卡只是为屏幕上显示像素提供一个缓存,所有的图形处理都是由CPU单独完成。图形渲染适合并行处理,擅长于执行串行工作的CPU实际上难以胜任这项任务。所以那时在PC上实时生成的三维图像都很粗糙。
1995年设计完成的3dfx Voodoo用自己的深度缓冲区(z-buffer)和纹理映射(texture mapping)技术将3D渲染速度提升到当时的顶峰。1999年发布GeForce 256图形处理芯片时首先提出GPU的概念,Geforce 256所采用的核心技术有硬体T&L、立方环境材质贴图和顶点混合、纹理压缩和凹凸映射贴图、双重纹理四像素256位渲染引擎等,而硬体T&L技术可以说是GPU的标志。

传统的GPU渲染流水线
从DirectX 9开始,ATI抢先发布了代号R300的Radeon 9700,这款GPU产品以简洁明快的设计风格赢得了用户的一致好评,首款DX9图形芯片,256Bit的显存位宽,9700凭借8条管线理所当然的坐上了3D之王的宝座。正是在由微软DirectX 9开启的R300时代,图形芯片厂商意识到了渲染管线的重要性。无论是顶点处理器数量还是像素渲染管线数量都成为各家厂商竞争的重点标准。如果说DirectX 8中的Shader单元还是个简单尝试的话,DirectX 9中的Shader则成为了标准配置。除了版本升级到2.0外,DirectX 9中PS单元的渲染精度已达到浮点精度,游戏程序设计师们更容易更轻松的创造出更漂亮的效果,让程序员编程更容易。
在图形处理中,最常见的像素都是由RGB(红绿蓝)三种颜色构成的,加上它们共有的信息说明(Alpha),总共是4个通道。而顶点数据一般是由XYZW四个坐标构成,这样也是4个通道。在3D图形进行渲染时,其实就是改变RGBA四个通道或者XYZW四个坐标的数值。为了一次性处理1个完整的像素渲染或几何转换,GPU的像素着色单元和顶点着色单元从一开始就被设计成为同时具备4次运算能力的算数逻辑运算器(ALU)。

“管线”的由来??1个时钟周期4次运算
顶点着色单元(Vertex Shader,VS)和像素着色单元(Pixel Shader,PS)两种着色器的架构既有相同之处,又有一些不同。两者处理的都是四元组数据(顶点着色器处理用于表示坐标的w、x、y、z,但像素着色器处理用于表示颜色的a、r、g、b),顶点渲染需要比较高的计算精度;而像素渲染则可以使用较低的精度,从而可以增加在单位面积上的计算单元数量。在Shader Model 4.0之前,两种着色器的精度都在不断提高,但同期顶点着色器的精度要高于像素着色器。
数据的基本单元是Scalar(标量),就是指一个单独的值,GPU的ALU进行一次这种变量操作,被称作1D标量。由于传统GPU的ALU在一个时钟周期可以同时执行4次这样的并行运算,所以ALU的操作被称作4D Vector(矢量)操作。一个矢量就是N个标量,一般来说绝大多数图形指令中N=4。所以,GPU的ALU指令发射端只有一个,但却可以同时运算4个通道的数据,这就是SIMD(Single Instruction Multiple Data,单指令多数据流)架构。
传统意义上像素渲染流水线(Pixel Shader Pipeline)应该是像素着色器(Pixel Shader Processor,简称PSP):纹理处理单元(Texture Model Unit,简称TMU):像素输出处理单元(Render Back End,简称RBE)=1:1:1。这个比例在DirectX 9.0c末期的Radeon 1900系列中被打破,因为ATI的工程师们认为在未来游戏中显卡Pixel Shader部分的ALU算术指令所占的比例将越来越大,TMU纹理贴图指令所占的比例将缩小。所谓3:1架构就是指Arithmetic:Texture=3:1或是ALU:TMU=3:1。(Arithmetic指算术运算,由ALU完成;Texture也可以指纹理运算,由TMU完成)。
无论是CPU送给GPU的顶点数据,还是GPU光栅生成器产生的像素数据都是互不相关的,可以并行地独立处理。而且顶点数据(xyzw),像素数据(RGBA)一般都用四元数表示,适合于并行计算。在GPU中专门设置了SIMD指令来处理向量,一次可同时处理四路数据,SIMD指令使用起来非常简洁。此外,纹理片要么只能读取,要么只能写入,不允许可读可写,从而解决了存贮器访问的读写冲突。GPU这种对内存使用的约束也进一步保证了并行处理的顺利完成。
产品:ATI Radeon HD 4850 显示芯片
传统SIMD结构流处理器指令细节
● 传统SIMD结构流处理器指令细节
传统的GPU基于SIMD的架构。SIMD即Single Instruction Multiple Data,单指令多数据。这种架构天生是为了应对顶点与像素四元组数据而设计的。
传统的VS和PS中的ALU(算术逻辑单元,通常每个VS或PS中都会有一个ALU,但这不是一定的,例如G70和R5XX有两个)都能够在一个周期内(即同时)完成对矢量4个通道的运算。比如执行一条4D指令,PS或VS中的ALU对指令对应定点和像素的4个属性数据都进行了相应的计算。这便是SIMD的由来。

R520架构顶点与像素着色器单元
这种ALU我们暂且称它为4D ALU。需要注意的是,4D SIMD架构虽然很适合处理4D指令,但遇到1D指令的时候效率便会降为原来的1/4。此时ALU 3/4的资源都被闲置。为了提高PS VS执行1D 2D 3D指令时的资源利用率,DirectX9时代的GPU通常采用1D+3D或2D+2D ALU。这便是Co-issue技术。这种ALU对4D指令的计算时仍然效能与传统的ALU相同,但当遇到1D 2D 3D指令时效率则会高不少,例如如下指令:
ADD R0.xyz , R0,R1
//此指令是将R0,R1矢量的x,y,z值相加 结果赋值给R0
ADD R3.x , R2,R3
//此指令是将R2 R3矢量的w值相加 结果赋值给R3
对于传统的4D ALU,显然需要两个周期才能完成,第一个周期ALU利用率75% ,第二个周期利用率25%。而对于1D+3D的ALU,这两条指令可以融合为一条4D指令,因而只需要一个周期便可以完成,ALU利用率100%。但当然,即使采用co-issue,ALU利用率也不可能总达到100%,这涉及到指令并行的相关性等问题,而且,更直观的,上述两条指令显然不能被2D+2D ALU一周期完成,而且同样,两条2D指令也不能被1D+3D ALU一周期完成。传统GPU在对非4D指令的处理显然不是很灵活。

R600之前SIMD流处理器常采用co-issue模式
传统的GPU中顶点和像素处理分别由VS和PS来完成,每个VS PS单元中通常有一个4D ALU,可以在一个周期完成4D矢量操作,但这种ALU对1D 2D 3D操作效率低下,为了弥补,DX9显卡中ALU常被设置为1D+3D 2D+2D等形式如上图。
为了进一步提高并行度,可以增加流水线的条数。多条流水线可以在单一控制部件的集中控制下运行,也可以独立运行。在单指令多数据流(SIMD)的结构中,单一控制部件向每条流水线分派指令,同样的指令被所有处理部件同时执行。SIMD架构可以用较少的晶体管堆积出庞大规模的流处理器,同时SIMD架构可以用最少的晶体管换取最大的浮点吞吐量值。但是在指令执行效率方面,SIMD架构非常依赖于将离散指令重新打包组合的算法和效率,正所谓有得必有失。
MIMD标量架构需要占用额外的晶体管数,在流处理器数量和理论运算能力方面比较吃亏,但却能保证超高的执行效率;SIMD超标量架构可以用较少的晶体管数获得很多的流处理器数量和理论运算能力,但执行效率方面要依具体情况而定。
产品:ATI Radeon HD 4850 显示芯片
MIMD结构流处理器指令细节
● MIMD结构流处理器指令细节
和ATI延续传统架构的思路形成非常明显的差异,NVIDIA在G80时代使用了全新的设计思想,它认为优化ALU阵列的结构才能换取更大的性能提升,而一味追求数量的增长无法永远延续较高的图形处理加速比。以下我们着重讨论G80和R600的统一着色单元而不考虑纹理单元,ROP等因素。
G80 GPU中安排了16组共128个统一标量着色器,被叫做stream processors,后面我们将其简称为SP。每个SP都包含有一个全功能的1D ALU。该ALU可以在一周期内完成乘加操作(MADD)。也许有人已经注意到了,在前面传统GPU中VS和PS的ALU都是4D的,但在这里,每个SP中的ALU都是1D标量ALU。

NVIDIA G80架构流处理器
这就是很多资料中提及的MIMD(多指令多数据)架构,G80走的是彻底的标量化路线,将ALU拆分为了最基本的1D 标量ALU,并实现了128个1D标量SP,于是,传统GPU中一个周期完成的4D矢量操作,在这种标量SP中需4个周期才能完成,或者说,1个4D操作需要4个SP并行处理完成。这种实现的最大好处是灵活,不论是1D,2D,3D,4D指令,G80得便宜其全部将其拆成1D指令来处理。指令其实与矢量运算拆分一样。

Fermi架构CUDA核心细节
例如一个4D矢量指令 ADD R0.xyzw , R0,R1 R0与R1矢量相加,结果赋R0
G80的编译器会将其拆分为4个1D标量运算指令并将其分派给4个SP:
ADD R0.x , R0,R1
ADD R0.y , R0,R1
ADD R0.z , R0,R1
ADD R0.w, R0,R1
ADD R0.y , R0,R1
ADD R0.z , R0,R1
ADD R0.w, R0,R1
综上:G80的架构可以用128X1D来描述。这种流处理器设计方式抛弃了单独追求浮点吞吐的目标,转而优化流处理器内部结构来换取更高的执行效率。但是它也有明显的问题就是需要使用更多发射端和周边寄存器资源来支撑这种被“打散”的流处理器运行,芯片集成度和面积相对于ATI都有较大提升,必须严格控制发热和功耗。
产品:ATI Radeon HD 4850 显示芯片
R600时代对SIMD架构补充与优化
● R600时代对SIMD架构补充与优化
R600的实现方式则与G80有很大的不同,它仍然采用SIMD架构。在R600的核心里,共设计了4组共64个流处理器,但每个处理器中拥有1个5D ALU,其实更加准确地说,应该是5个1D ALU。因为每个流处理器中的ALU可以任意以1+1+1+1+1或1+4或2+3等方式搭配(以往的GPU往往只能是1D+3D或2D+2D),co-issue模式的应用更为灵活。

R600到R800统一渲染流处理器架构
ATI将这些ALU称作streaming processing unit,因而,ATI宣称R600拥有320个SPU。我们考虑R600的每个流处理器,它每个周期只能执行一条指令,但是流处理器中却拥有5个1D ALU。ATI为了提高ALU利用率,采用了VLIW体系(Very Large Instruction Word)设计。将多个短指令合并成为一组长的指令交给流处理器去执行。例如,R600可以5条1D指令合并为一组5DVLIW指令。

R600时代庞大的320个流处理器阵列
对于下述指令:
ADD R0.xyz , R0,R1 //3D
ADD R4.x , R4,R5 //1D
ADD R2.x , R2,R3 //1D
ADD R4.x , R4,R5 //1D
ADD R2.x , R2,R3 //1D
R600也可以将其集成为一条VLIW指令在一个周期完成。
综上:R600的架构可以用64X5D的方式来描述。
G80将操作彻底标量化,内置128个1D标量SP,每个SP中有一个1D ALU,每周期处理一个1D操作,对于4D矢量操作,则将其拆分为4个1D标量操作。R600仍采用SIMD架构,拥有64个SP,每个SP中有5个1D ALU,因而通常声称R600有320个PSU,每个SP只能处理一条指令,ATI采用VLIW体系将短指令集成为长的VLIW指令来提高资源利用率,例如5条1D标量指令可以被集成为一条VLIW指令送入SP中在一个周期完成。
产品:ATI Radeon HD 4850 显示芯片
● 两种结构流处理器优劣对比
两种结构流处理器优劣对比
现在的AMD,最大的追求就是在尽可能保证小尺寸核心的基础上,提供尽可能多的性能。或者这话应该换一种方式说??堆垛晶体管的临界点,出现在增加晶体管所导致的性能增加出现拐点的那一刻。当堆垛晶体管所能够换来的性能增幅明显下降的时候,就停止堆垛晶体管。
疯狂的ALU运算器规模堆砌,让NVIDIA毫无招架之力,同时坚持以效率致胜的MIMD结构流处理器长期无法摆脱晶体管占用量大的烦恼,运算器规模无法快速增长。Fermi架构完全放弃了一味追求吞吐的架构设计方向,这一点在通用计算或者说复杂的Shader领域值得肯定,但是遇到传统编程方式的图形运算,还是因为架构过于超前显得适应性不足。
RV770可以说是AMD化腐朽为神奇的力作,较之R600,RV770不仅将公共汽车一般缓慢的Ringbus换成了高速直连的Crossbar,而且还追加了大量的资源,比如为16个VLIW CORE配置了16K的Local Data Share,同时将原有的Global Data Share容量翻倍到了16K,在此基础上,还将VLIW CORE规模整体放大到了R600的250%(320个提升到800个),另外,在后端配置的RBE单元以及更加完善的TA/TF也促成了RV770的脱胎换骨。

GT200和RV770运算单元架构
在扩展ALU资源的基础之上,AMD还在做着另外一件事,那就是尽一切可能逐步优化较为古老和低效的SIMD结构。在RV7中对LDS的空间直接读写操作管理等改进就是这类努力地开始。这导致了R600和R700在Shader Program执行方面有很大差别。R600的Shader Program是Vertical Mode(5D)+Horizontal Mode(16x5D)的混合模式。而RV770是单纯的Vertical Mode(16x4D=64D & 16*1D=16D,即64D+16D)。
简单的说,RV770更加趋紧于NV50 Shader Unit的执行方式,而R600则相去甚远。总的来说,NV更加趋紧于使用基于硬件调度器的Superscalar方式来开发ILP,而AMD更加趋紧于基于软件编译器调度的VLIW方式来开发ILP。

AMD RV870芯片显微照片与功能分析
到了RV870架构,AMD控制甚至紧缩资源,然后靠制程来拼规模,并最终让SIMD尽可能接近通过暴力吞吐掩盖延迟的最理想结局。然后就出现了我们现在看到的拥有1600个流处理器,体积却依然小于Fermi架构GF100的Radeon HD5870显卡。
AMD从R600核心开始,一直延续着上述理念设计GPU产品,R600身上有很多传统GPU的影子,其Stream Processing Units很像上代的Shader Units,它依然是传统的SIMD架构。这些SIMD架构的5D ALU使用VLIW技术,可以用一条指令完成多个对数值的计算。
由于内部的5个1D ALU共享同一个指令发射端口,因此宏观上R600应该算是SIMD(单指令多数据流)的5D矢量架构。但是R600内部的这5个ALU与传统GPU的ALU有所不同,它们是各自独立能够处理任意组合的1D/2D/3D/4D/5D指令,完美支持Co-issue(矢量指令和标量指令并行执行),因此微观上可以将其称为5D Superscalar超标量架构。

AMD的流处理器结构变化
SIMD虽然很大程度上缓解了标量指令执行效率低下的问题,但依然无法最大限度的发挥ALU运算能力,尤其是一旦遇上循环嵌套分支等情况,SIMD在矢量处理方面高效能的优势将会被损失殆尽。同时VLIW的效率依赖于指令系统和编译器的效率。SIMD加VLIW在通用计算上弱势的原因就在于打包发送和拆包过程。
NVIDIA从G80开始架构作了变化,把原来的4D着色单元彻底打散,流处理器不再针对矢量设计,而是统统改成了标量运算单元。每一个ALU都有自己的专属指令发射器,初代产品拥有128个这样的1D运算器,称之为流处理器。这些流处理器可以按照动态流控制智能的执行各种4D/3D/2D/1D指令,无论什么类型的指令执行效率都能接近于100%。
AMD所使用的SIMD结构流处理器,具有非常明显的优势就是执行全4D指令时简洁高效,对晶体管的需求量更小。而NVIDIA为了达到MIMD流处理器设计,消耗了太多晶体管资源,同时促使NVIDIA大量花费晶体管的还有庞大的线程仲裁机制、端口、缓存和寄存器等等周边资源。NVIDIA为了TLP(线程并行度)付出了太多的代价,而这一切代价,都是为了GPU能更好地运行在各种复杂环境下。