超越图形界限 AMD并行计算技术全面解析(三)

我们使用GPC Benchmark 1.1对当前ATI和NVIDIA顶级GPU做理论浮点运算能力测试,测试选择了最具代表性的浮点吞吐项目,分别是单精度加法、单精度乘法、单精度乘加、密码学SHA-1哈希加密。我们选择了10.3正式版驱动(AMD Radeon HD 5870)和256正式版驱动(NVIDIA GeForce GTX 480)测试平台如下:
| 测 试 平 台 硬 件 | |
| 中央处理器 | Intel Core i7-870 |
| 散热器 | Thermalright Ultra-120 eXtreme |
| 内存模组 | G.SKILL F3-12800CL9T-6GBNQ 2GB*2 |
| (SPD:1600 9-9-9-24-2T) | |
| 主板 | ASUS P6T Deluxe |
| (Intel P55 + ICH10R Chipset) | |
| 显示卡 | |
| 测 试 产 品 | |
| GeForce GTX 480 | |
| (GF100 / 1536MB / 核心:700MHz / Shader:1401MHz / 显存:3696MHz) | |
| Radeon HD 5870 | |
| (RV870 / 1024MB / 核心:850MHz / Shader:850MHz / 显存:4800MHz) | |
| GeForce GTX 285 | |
| (GT200 / 1024MB / 核心:648MHz / Shader:1476MHz / 显存:2848MHz) | |
| Radeon HD 4870 | |
| (RV770 / 1024MB / 核心:780MHz / Shader:780MHz / 显存:3700MHz) | |
| 硬盘 | Western Digital Caviar Blue |
| (640GB / 7200RPM / 16M | |
| 电源供应器 | AcBel R8 ATX-700CA-AB8FB |
| (ATX12V 2.0 / 700W) | |
| 显示器 | DELL UltraSharp 3008WFP |
| (30英寸LCD / 2560*1600分辨率) | |

GPC Benchmark 1.1吞吐项目测试结果
除了底层性能的检测软件之外,我们还使用了SiSoftware Sra 2010版软件来检测显卡所搭载的GPU理论浮点吞吐量。这个测试可以检测GPU的Shader单元运算能力,虽然它是面向通用计算程序设计的,但是在一些较为高端的对Shader负载较重的游戏中,Shader单元运算能力强的显卡可以有更强劲的发挥和更小的性能衰减。

SiSoftware Sra 2010 GPGPU Processing项目浮点吞吐
需要注意的是这里检测的仅是理论浮点值,实际运算环境中将会包含大量跳转嵌套分支等指令,只有运算器组织得当的GPU,才能有效避免理论值的大幅度衰减。测试对N卡和A卡则给予了可选择的接口支持,所以测试结果无论是对于NVIDIA还是AMD都比较公正。我们使用的版本号是16.36.2010,测试方法是进入程序后,选择界面中的Benchmark工具,然后选择GPGPU Processing项目。
ATI GPU OPEN CL综合性能分析
● ATI GPU OPEN CL综合性能分析
上一节我们使用两种软件考察了ATI GPU的吞吐特性,这个测试结果佐证了我们之前对于ATI GPU架构的相关分析,接下来我们将通过OpenCL通用计算测试程序OpenCL General Purpose Computing Benchmark (简称GPC Benchmark OCL)1.1版本全部项目来测试NVIDIA和ATI顶级单卡单芯性能,我们选择了10.3正式版驱动(AMD Radeon HD 5870)和256正式版驱动(NVIDIA GeForce GTX 480)。
在测试之前有必要对本次测试项目做简单介绍:首款国人开发的支持GPU的OpenCL通用计算测试程序OpenCL General Purpose Computing Benchmark (简称GPCBenchMarkOCL)是由国内几名高性能计算从业人员和爱好者合作编写的,目的是为了评估在不同的OpenCL平台上一些基本算法和应用的性能。与目前流行的一些OpenCL、DirectCompute通用计算测试程序的不同在于,目前这些测试程序测试项目过于单一,基本上就是某一两种算法的性能测试,甚至干脆就是理论峰值计算性能的测试。
而实际上,OpenCL计算设备包括GPU的计算性能是受非常多因素影响的,除了计算单元的频率和数量之外,还有计算单元架构、Global memory(显存)带宽、Local memory(GPU内的片上存储器,NVIDIA称为Shared memory,AMD称为Local Data Share)带宽和Bank conflict、存储器合并访问情况、存储器同步成本、缓存等各种因素。因此某些纸面计算性能非常高的GPU执行某些计算时性能却不一定好;又或者,某GPU在执行某种计算时虽然性能落后于另一架构的GPU,但是在执行另一种计算时性能反而超前。GPCBenchMarkOCL集合了高性能计算领域多种常见的基础算法和应用,能比较全面地评估GPU及其它OpenCL计算设备在通用计算应用中的性能。

GPCBenchMarkOCL软件界面
目前GPCBenchMarkOCL的测试项目包括:
1、Global Memory带宽(读、写、拷贝以及PCI-E总线带宽) - 主要考察不同传输尺寸下各种访存操作的性能
2、Local Memory带宽(带宽和Bank conflict) - 分析Local memory带宽与数据类型、Bank conflict的关系
3、32位整数性能(加法、乘法、乘加和位运算) - 分析处理器32位整数处理性能
4、单精度浮点性能(加法、乘法、乘加和特殊函数如sqrt、sin等) - 分析处理器单精度浮点数处理性能
5、双精度浮点性能(加法、乘法、乘加和特殊函数如sqrt、sin等) - 分析处理器双精度浮点数处理性能
6、常用计算(单精度和双精度浮点的大矩阵乘法、大矩阵转置、归约、DCT8x8) - 分析处理器在进行一些常用矩阵与信号处理运算中的表现
7、图像处理(亮度直方图、2维卷积、降噪、双立方插值缩放) - 分析处理器在进行一些常用图像处理中的表现
8、密码学(目前只有SHA-1 Hash Loop,以后将加入盒型加密和彩虹表) - 分析处理器在密码学应用中的性能。
在GPCBenchMarkOCL中,所有测试都会在CPU和GPU(包括其它OpenCL设备)上运行并给出性能结果,不过CPU上运行的并非OpenCL代码而是用常规C语言实现的并行算法(会调度全部的CPU核)。而GPU上运行的OpenCL代码经过试验能正确运行在NVIDIA GTX285和AMD HD5870上。各算法的OpenCL实现有部分修改自NVIDIA和AMD的SDK,部分是由相关从业人员和爱好者提供的。
由于NVIDIA和AMD的GPU架构上有很大区别,对于某些算法也许能专门针对NVIDIA或AMD的GPU架构写出非常难看的比较极端优化的OpenCL代码,但考虑编程难度、程序的可读性和普遍意义,GPCBenchMarkOCL只使用了一般的GPU编程优化方法做了简单优化(例如使用Local memory暂存数据、利用合并访问规则等),并且在不同的OpenCL计算设备上也是运行相同的OpenCL代码来进行测试。这保证了GPCBenchMarkOCL是目前比较容易找到的较为干净的测试软件,它可以真实反映硬件特性对不同数据类型的适应程度,这一点最重要。
GPCBenchMarkOCL支持AMD RV770及Evergreen(R800)系列,以及NVIDIA G8x、G9x、GT200、GT21x、GF100等GPU的OpenCL平台。我们选用的测试平台同上一节。

GPCBenchMarkOCL所有项目测试结果
分析上图得到的测试数据我们可知,在纯吞吐环境中,AMD延续了R600架构以来的特性,其浮点吞吐量的优势得以体现。特别是浮点运算(单精度)测试中,HD5870压制了强大的Fermi架构GTX480。在密码学测试中,因为很少牵扯到计算层面,GPU只是不断随即生成数据然后去试探,所以A卡理论吞吐量高的特性再次得到体现。
但是只要涉及到常规数学方法测试,这种实际运算环境中将会包含大量跳转嵌套分支等指令,只有运算器组织得当的GPU,才能有效避免理论值的大幅度衰减。A卡因为其架构设计原因,大幅度落后于Fermi架构。
其中HD5870落后最为明显的图像处理,包括亮度直方图绘制、2维卷积(锐化)、快速非局部均值法降噪、图片缩放(双立方滤波)。这项测试主要考虑GPU的全局存储器和纹理访问能力,同时局部存储器原子操作也占到一定比重,所以架构较新的Fermi系列产品表现优异。

GPCBenchMarkOCL测试总评
我们将涉及存储器的测试归类到存储总评,密码学和单双精度浮点乘加归类到吞吐总评,图像处理和单双精度图形处理归类到计算总评,得到以上测试结果。这个结果可以非常直观地告诉我们在浮点吞吐中,R800由于其SIMD核心内的5D ALU采用VLIW技术,所以遇到规范的数据类型时可以表现出近乎满载的效率,而NVIDIA从G80到GF100芯片都面临吞吐量受制于流处理器结构的影响。
但是一旦牵扯到包含大量跳转嵌套分支等指令的常规数学方法测试,NVIDIA对ALU阵列的组织形式优化立刻体现出优势,此时AMD的VLIW Cores无法满载运行,每一时刻都有大量运算单元空闲。
另一个值得注意的地方就是NVIDIA GPU在局部存储器和全局存储器测试中表现优异,特别是全局存储器在197-257的驱动升级中提升了将近50%,这充分反映了GPU加入通用Cache的重要性。这里的局部存储器是寄存器到cache或者shared memory,全局存储器是cache或者shared memory到显存。我们估计NVIDIA优化了Cache的命中率。cache的命中来自对内存系列也就是显存的命中,所以GPU的整体效率会受益于Cache单元的不断优化。
先进混合架构之Larrabee展望
● 先进混合架构之Larrabee展望
早在1998年2月,Intel发布了和Real3D合作设计的i740/i752独立显卡,虽然该产品在当时性能没有达到领先,但是凭借强大的推广与Intel自身的大厂优势,确实让其独立显卡红极一时。但由于各大竞争对手的3D显卡性能遥遥领先,加上Intel忙于自己的平台化策略,风光一时的i740/i752成为Intel独立显卡的“绝唱”。
相隔十多年,Intel在平台化战略中取得了巨大成功,Intel在集成显卡市场的占有率超过了50%,从810/815系列到845/865系列,再到G41/H55系列主板芯片组,Intel的集成显卡战略所向披靡。Larrabee计划正是在此背景下提出,它将向世人证明Intel拥有开发高端独立显卡的能力,同时巩固市场占有率,改变人们对其显卡视为“鸡肋”的看法。同时Larrabee还肩负开拓GPU通用计算市场的重任,Intel希望这款GPU能够有效抵御NVIIDA和AMD对于并行计算市场的侵蚀。
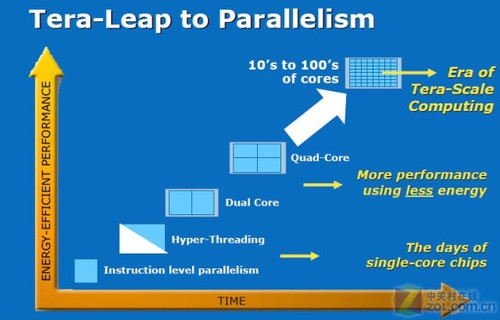
Larrabee属于单芯片TFLOPS级别运算项目
Intel使用CPU经典原理和最新技术改良了传统GPU,使其集成了数目可观的X86核心,并采用顺序执行,同时辅以先进的CSI总线和高速存储系统,形成了Larrabee芯片概念。Larrabee芯片隶属于Tera-Scale项目,是一块融入的诸多先进技术的GPU。对于图形工业而言,Larrabee是一款具有革命意义的产品,它与常规的意义上的GPU存在理念上的差异,即Larrabee将通用计算性能放在优先位置。Intel高级副总裁Pat Gelsinger表示,Larrabee是一种可编程的多核心架构,采用顺序执行架构(CPU为乱序执行核架构),并使用经过调整的x86指令集,在运算性能上将达到万亿次浮点运算的级别。
Intel之所以会这样设计Larrabee硬件架构,出于以下几个方面的考虑,或者说Larrabee有以下几项显著特点:
1、X86架构核心:GPU在可编程方面的劣势恰好是CPU的优势,GPU不断追求的可编程性对于CPU则非常容易。CPU只要采用相应的指令集结构就可以支持采用该指令集编写的所有程序,而不必理会用户的软件使用环境。

Larrabee使用X86架构作为根基
如图Larrabee芯片架构。当然,相对于GPU提供完美的可编程性正是X86架构的特性。Intel的X86架构通常被称作IA架构,它主要由存储控制部分、前端解码器部分、执行单元部分构成。所有基于CISC的代码都将经过解码器并翻译为类似RISC的样式,高效的译码系统会保证CPU接收到自己完全可以执行的RISC风格代码,有利于简化处理器执行流水线的设计,而且在提高性能的同时能确保兼容性。
Larrabee使用X86架构一方面由于Intel多年的技术积累可以轻松驾驭芯片的逻辑设计,另一方面我们也要看到Intel已经将目光放在更长远的通用计算领域,它要通过完美的可编程性来达到比竞争对手更优秀的兼容性,更大程度上拓展通用计算的应用范围。相较于 GPGPU(甚至是自家的 80 核处理器,也不是采用 X86 架构发展的)目前多数的软件工程师仍不熟悉如何将 GPU 应用在多任务处理及平行运算上,Larrabee将在普及大规模并行运算上占有很大优势。
2、顺序执行单元:Larrabee所使用的X86架构不同于目前CPU的重要区别是顺序执行。在很早以前的顺序执行CPU中,当装载指令队列发生等待时,处理器不能将队列后方处于等待的指令优先装载并执行,一直等待到堵塞结束。平均而言约30%的指令会发生一定时间的堵塞,这种执行方式叫做顺序执行,显然降低了执行单元的效率。乱序执行在1995年的Pentium Pro处理器上首先实现,它可以最大限度利用资源,这种设计一直沿用至今,Core微架构可以说实现了目前最高水准的乱序执行。

传统CPU采用晶体管消耗较大的乱序执行单元
而这次Intel在Larrabee设计中重新引入顺序单元,是有充分理由的。顺序执行让一条线程中的各个指令根据其原有顺序逐一执行,这样芯片内部就完全无需加入用于指令分析和运算结果合成的逻辑,从而极大地减少晶体管使用量。而效率低下的问题使得业界一致认为乱序执行要强于顺序执行。但最近几年,随着高频率和多线程技术的不断发展,许多厂商认为顺序执行的单线程性能低下优势已经可以通过增加线程和提高频率来弥补,反而晶体管使用过量会造成发热和功耗很难控制。
Intel根据对比得到,乱序执行内核需要至少50平方毫米的面积,最少37.5W功耗。而使用了顺序执行,单个内核面积只有10平方毫米,功耗也下降到6.25W。在Intel的实验芯片上,使用顺序执行与VLIW指令集,在10平方毫米的面积上可同时运行4条线程和16个512bit向量,最终达到128 GFLOPS的浮点运算性能。面对Tera-Scale项目要求的TFLOPS性能目标,在顺序执行的X86核心思想下,只需多个核心即可完成。
但是业界对于Larrabee这颗芯片的观点还是众说纷纭:AMD指出如果Larrabee处理器的通用性是基于适合流处理器而进行设计的话,那么其图形性能将不足以使其成为一款专业的GPU产品,另外就是我们还必须考虑到其图形处理器性能也不会很高。
有一种观点认为X86架构限制了CPU性能的发展,但是所谓限制不能光看硬件。如果这套架构能给编程者提供统一完善的可操作性强的编译环境和在这个环境下相对充沛的资源,那这个构架即不是效率最高的构架,但却是目前环境下唯一理想的构架。
也有评论家认为X86的指令集通用性会更好一些,但是并不适合于并行处理。而对于AMD公司的Fusion则是将X86的CPU与GPU核心进行合并,这样CPU可用于一般数据处理,而GPU核心可以进行并行数据处理,从而可以实现最优化处理。简单的说就是AMD保持了X86 CPU和GPU各自的特征。这样避免了过大的新技术开发投入,现有软件也能够更好地使用其Fusion处理器资源。
NVIDIA也有自己的打算,该公司也没有明确表示将来是否在GPU产品上加入对X86指令集的支持,这也是NVIDIA公司与另外两家CPU生产厂商间的关键差异。NVIDIA表示其没有X86核心绝不能算作是弱点,NVIDIA相信自己所选择的发展方向,其Tesla计划正在加紧推进,目前在高性能计算领域已经打开市场。同时NVIDIA正在进行据并行处理最佳指令集的研发,计划进一步扩充GPU的性能,这一代的Fermi架构GF100芯片已经轻松达到1TeraFLOPS的单精度浮点运算性能,双精度浮点的衰减也控制在单精度浮点性能的1/2。
概念型融合架构之Fusion APU展望
● 概念型融合架构之Fusion APU展望
在2006年10月25日,AMD完成对ATi的收购后就公布了“Fusion”架构,并预计在2009年底或2010年发布,成为K10微架构的后继者。Fusion架构同时也是Torrenza统一加速计算平台的一部分,配合FireStream流处理器进行协同运算。Fusion架构预计内置一颗中低端GPU,这样这款CPU就可以独立完成PC系统内的各项工作,这就是AMD提出的APU(Accelerated Processing Units)概念。

Fusion架构logo
AMD Fusion是AMD与ATI合并后推出的一项新产品的产品代号,它结合了现时的处理器和绘图内核,在处理器进行图像和三维(3D)运算。AMD Fusion的硅芯片上有两个独立的内核,一个负责处理器,另一个负责绘图内核,两个内核而不是融合在一起。处理器有自己独立的缓冲存储器,绘图内核部分同样如此。两个内核会通过CrossBar互相连接。此外,Fusion亦会集成存储器控制器。Fusion中的各个组件之间使用HyperTransport连接,使各个组件连接成一个整体。处理器和绘图内核可以直接访问存储器,但绘图内核没有独立的显示存储器。南桥不会集成在Fusion芯片中。

APU相对于CPU和GPU的特性
APU融合有很多种方向可以发展,既可以把低端显卡整合进CPU,又可以通过CPU的L3让GPU与CPU的联系更加紧密。最终,SP可以被慢慢的剥离出来单独使用,既可以加强FPU,又可以干一些指令集干的事情,或者说达到一些指令集操作才能达到的结果,比如更大的运算能力。
在AMD现阶段无法开发出效率极高的指令集时,用硬件单元来补足执行效率的不足是非常明智的选择,Fusion架构的代表APU就是这种思路下的产物。毕竟开发指令集需要对硬件架构做出优化,寄存器和相关资源都需要进一步放大,这也需要增量晶体管来辅助。而整合GPU则意味着AMD可以把ATI GPU中的流处理器单元直接变为浮点运算器(FPU)。这样的整合会相对简单,同时Intel和NVIDIA由于技术上的缺失都无法涉足。
从上图我们可以获知,APU将芯片内的不同物理单元抽象成两个逻辑部分,分别是串行计算单元和并行计算单元。我们知道这分别是传统CPU和GPU 的两大特性。APU使用一颗类似SoC概念的芯片设计,让不同层面的用户在低端市场上同样能够获取到“异构计算”(heterogeneous computing)能力,这是对于独立CPU+独立GPU计算的重要补充。
GPU进化架构之Fermi分析
● GPU进化架构之Fermi分析
GT200发布时其宣传口号是所谓的Gaming Beyond和Computing Beyond,这个宣传口号第一次鲜明地体现了NVIDIA的GPU设计方向发生了明显变化。GPU Computing概念的提出,说明了GPU身份已经转变为一颗通用计算处理器。同时NVIDIA需要为开拓GPU通用计算市场而做出一些设计方面的变化。

而不久前发布的Fermi架构GTX400系列显卡,正是这一概念的深刻体现。代号GF100的Fermi设计方案在4年前确定下来并付诸行动,这时正值代号G80的Geforce 8800GTX做最后的出厂准备。G80凭借全新的MIMD(多指令流多数据流)统一着色器(又称流处理器)获得了业界的一致认同,同时被业界关注的还有G80的通用计算性能。
NVIDIA的Tony Tamasi先生(NVIDIA高级副总裁,产品与技术总监)表示:“以前的G80架构是非常出色的图形处器。但Fermi则是一款图形处理同样出色的并行处理器。”
这句话揭示了Fermi的与众不同,它已经不再面向图形领域设计了,因为更广阔的通用计算市场在等待它。Fermi将为通用计算市场带来前所未有的变革,图形性能和游戏被提及已经越来越少。

NVIDIA公司在不断强调并行计算的重要性
从NVIDIA处理器架构的发展来看,Tamasi先生的话意思很清楚。回顾历史我们可以发现NVIDIA最近几年间,大规模改进图形处理架构设计的是GeForce 6000(NV40)系列,之后就是GeForce 8000(G80)和GeForce GTX 200(GT200),最后就是Fermi。
“CUDA Cores”是Fermi最基础的运算单元,将它的历史向上追溯首先是G80时代的统一着色单元(Unified Shader Model),我们在G80和GT200时代将它统称为流处理器(Stream Processor),再向上追溯可知,这个单元将Vertex Shader(顶点着色器)和Pixel Shader(像素着色器)合并而成。
理论上说“CUDA Cores”只是起了一个好听的名字,让人们更看重GPU通用计算的作用,实际上我们在图形领域还是将它视为普通的流处理器。但这背后透露出NVIDIA公司的另一种计划??面向并行计算领域设计一颗芯片,并使其具备图形运算能力,这颗芯片由众多的“CUDA Cores”组成,运算速度主要由“CUDA Cores”的数量和频率决定。
在没有了解Fermi的核心构成之前,很多人“CUDA Cores”概念嗤之以鼻,认为这是NVIDIA公司的营销策略,就像HD5870所拥有的1600个流处理器一样,实际上是320个SIMD单元。两家公司确实打了不少口水仗,无数玩家也跟着它们提出的概念升级了自己的显卡。不过这次Fermi改变名称和设计方向,是有备而来的。
Fermi架构视频解析
NVIDIA这次敢提出图形性能和通用计算并重,说明GPU设计的重点和难点都在通用计算方面而非图形。因为一颗已经演化了十年的GPU肯定能做好自己的老本行图形计算,但是要做通用计算,需要更强大的线程管理能力,更强大的仲裁机制,丰富的共享cache和寄存器资源以及充足的发射端……如果做不好这些东西,GPU永远都是PC中的配角,永远都是一颗流处理器。这些表面上看这些部件是极占晶体管的东西,更可怕的是设计这些部件需要太多科研成本和时间。
Impress Watch网站知名IT评论人後藤弘茂称NVIDIA全新Fermi架构,是以处理器为目标进行设计的。因为你在Fermi身上可以看到以前GPU上从来没有的东西,包括更多的指令双发射、统一的L2全局缓存、64KB的可配置式L1或者Shared Memory、大量的原子操作单元等等。
第五章:ATI GPU通用计算实例
● 第五章:ATI GPU通用计算实例分析
前四章我们分析了GPU并行计算的技术基础和不同架构之间的性能差异。我们特别对ATI GPU从R300到R600的沿革和R600到现在R800的优化做了分析,让大家明白ATI GPU架构在哪些方面有出人意料的表现,哪些方面则表现地落后于竞争对手。在本章,我们将使用较小的篇幅来展示目前GPU并行计算编程方面的新进展,特别是GPU并行编程API的相关发展情况。
让我们把时间调回到2003年,当时正值Shader Model 2时代。随着GPU计算能力的不断增长,一场GPU革命的时机也成熟了。Shader模型的不断发展使得GPU已经从由若干专用的固定功能单元(Fixed Function Unit)组成的专用并行处理器,进化为了以通用计算资源为主,固定功能单元为辅的架构,这一架构的出现奠定了GPGPU的发展基础。

SIGGRAPH 2003大会开始深入研究GPU通用计算
当时在圣迭戈举行的SIGGRAPH 2003大会上,许多业界泰斗级人物发表了关于利用GPU进行各种运算的设想和实验模型。SIGGRAPH会议还特地安排了时间进行GPGPU的研讨交流。在2004年9月份,剑桥大学的BionicFx课题组便宣布在NVIDIA的GeforceFX 5900产品中实现了专业的实时音频处理功能,并且准备进行商业化的运作,对其产品进行销售,给音乐创作者带来实惠。
在随后的一段时间,GPGPU进入了深入研究阶段,但是由于编程语言架构和编程环境都难以通用,该领域的发展能力受到广泛质疑。就在人们认为GPGPU的研究即将偃旗息鼓的时候,ATI在2006年8月惊人地宣布即将联手斯坦福大学在其Folding@Home项目中提供对ATI Radeon X1900的支持。在显卡加入Folding@Home项目后,科研进展速度被成倍提升,人们第一次感受到了GPU的运算威力。
毫无疑问,在GPGPU研究上,ATI跨出了极具意义的一步。同时将GPGPU的应用领域和普及程度推向高潮。随后NVIDIA凭借GeForce 8800GTX这款业界首个DirectX 10 GPU,在GPU通用计算方面实现了大步跨越,特别是CUDA概念的提出(该工具集的核心是一个C语言编译器),在新的通用计算领域后来居上。
未来科学和工程的关键在于并行计算
GPU在很多领域的研究中已经开始发挥作用。支持DirectX 10显卡的首次出现是一个分水岭:过去只能处理像素或者只能处理顶点的专门功能处理单元被通用的统一着色器架构(Unified Shader Architecture)取代了,开发人员可以更轻松的对统一着色器进行控制。以AMD R600和NVIDIA G80为代表的DirectX10时代GPU能够提供了超越以往任何GPU的能力:它们拥有数百个功能单元,能够处理很多过去只能在CPU上运行的并行问题。
GPGPU将应用范围扩展到了图形之外,无论是科研教育、财务计算,还是在工业领域,GPGPU都得到了广泛的使用,关于它的科研成果和新应用模式也层出不穷。许许多多令人鼓舞的结果已经表明:将GPU用于解决数据并行计算问题可以明显提高系统的运行速度。本章我们会对目前炙手可热的GPU并行编程API做简单介绍,同时向用户推荐几种基于ATI GPU产品的通用计算项目,他们基于开放式的BOINC平台或者形成独立的开放式平台,我们可以通过下载软件来参与这些项目体验GPU通用计算带给业界的变革。
ATI Stream技术发展与现状
● ATI Stream技术发展与现状
ATI Stream技术是一套完整的硬件和软件解决方案,这个概念最初在2005年依据R580核心的流处理加速卡提出。随后ATI被AMD收购,异构计算概念被越来越多的提及,Stream技术被定义为能够使AMD图形处理器(GPU)与系统的CPU协同工作,加速处理图形和视频以及其他大量应用。该技术使更加平衡的平台能够以前所未有的速度运行要求苛刻的计算任务,为最终用户提供更出色的应用体验。

两家GPU厂商提出的通用计算解决方案
无论是NVIDIA还是AMD,都正在与领先的第三方行业合作伙伴和全球范围的学术机构一起,建立完整的GPU计算生态系统。AMD系统通过Stream技术能够提供实现AMD低成本应用加速所必需的性能、应用、软件和工具。我们也不得不意识到两家公司在计算机专业领域的影响力是不可估量的,因为它们能通过GPU提供更好的并行计算加速比。

ATI Stream技术软件环境
Brook+是AMD出的显卡编程语言,它和NVIDIA提出的CUDA C是对应的。只不过CUDA的基础是C和C++,而brook+是汇编。brook+环境下写程序不是那么容易的,毕竟它属于低级语言,但是那是程序员和推广的问题,一旦写出来了效率通常都很高的。所以说汇编是底层语言,效率很高但是兼容性和简易型较差。
ATI Stream技术定义程序可以被分为两种,也就是图中的库,以及第三方代码。库可以直接转化成brook+,第三方代码则需要通过stream编译一下。编译好的东西可以直接丢给CPU或者GPU算。其中绿色的是计算抽象层规则。这张图片说明ATI GPU可以通过计算抽象层规则直接运行程序,也可以通过OCL来支持应用程序,也就是说OCL只是其中一种选择。实际上AMD倒向OCL,应该也有打算让自己以第一的身份接近OCL制定者并影响对方甚至施压的意思。CUDA和Stream都是编译环境,而OpenCL跟DirectX都是API。

Brook+语言元素
从特性方面分析,Stream是基于一种传统的编程方式,Stream主要包括CAL与Brook+。CAL是一套指令集,可以用汇编语言的方式来开发软件,虽然我们汇编方式开发软件的话,对搞计算的人来说不大现实,让他们用汇编语言来说的话可能确实是一种折磨,但是这种方式更为接近硬件,合理优化可以大幅度提升运算效率。Brook+是斯坦福大学开发的,它是类似于C语言的东西,是把底层GPGPU的计算方式类似于C的这种语言,这里要说明的是Brook+不是C语言而是类C语言,语法和C语言比较类似。

Stream技术GPU硬件基础
从R600到R800时代,的每个流处理单元都包含5路超标量体系结构着色处理器,单时钟周期可以最多处理5个标量乘加指令,其中一路着色处理器负责处理超越指令(比如Sin、Cos、Log、Exp等等)。我们看下图就可以明白,5个黄色的长方形就是5路着色处理器,其中较大的一个就是可以处理超越指令的着色处理器。流处理单元可以达成32-bit浮点精度,支持整数和逐位操作,图中紫色的长方形“分支执行单元”则负责进行流控制和条件运算。
OPEN CL接口技术与异构运算
● OPEN CL接口技术与异构运算
2010年8月16日,AMD宣布推出全面支持OpenCL 1.1的ATI Stream软件开发包(SDK)2.2版,新版本的SDK为开发人员提供开发强大的新一代应用软件所需要的工具。这一版本的最大意义在于它表明了AMD在不断追求与开放性应用程序接口OpenCL的兼容,同时AMD再通过OpenCL快速提升其在业行内的影响力,毕竟借助这一标准,AMD和NVIDIA站在了统一起跑线上,OpenCL接口对于一个技术与标准的追随者来说是千载难逢的机会。

著名的开发组织Khronos发布了OpenCL(Open Computing Language)
在Open CL发布之前,AMD/ATI支持BrookGPU模式,并有了升级版本的SDK Brook+。虽然Brook+可以实现GP-GPU计算,但是整个行业已经意识到需要出台某种标准。作为图形芯片的两大巨头,NVIDIA拥有自己的CUDA架构,AMD有自己的Stream架构,同时本次他们又是OpenCL的支持者。在OpenCL标准发布之后,AMD和NVIDIA立即表态,宣布即将采用OpenCL 1.0编程规范。AMD正在不断将合适的编译器和运行库整合进免费的ATI Stream软件开发包(SDK),作为OpenCL的创始人之一,AMD一直以来都极力推崇OpenCL,并在2009年上半年开发出ATI Stream SDK的开发者版本,实现对OpenCL 1.0的支持,如今ATI Stream软件开发包(SDK)2.2版的发布进一步支持这一标准向前推进。

OpenCL标准的支持者
OpenCL对开发者、业界人员和消费者来说都是一个非常好的API,它可以使得开发者很容易的开发出跨平台的GPU计算程序,充分利用GPU强大的计算能力然后应用在各种领域。同时OpenCL对于异构运算的支持也开始明朗化。

OpenCL标准所提倡的CPU-GPU异构计算
我们知道CPU和GPU各有所长,一般而言CPU擅长处理不规则数据结构和不可预测的存取模式,以及递归算法、分支密集型代码和单线程程序。这类程序任务拥有复杂的指令调度、循环、分支、逻辑判断以及执行等步骤。例如,操作系统、文字处理、交互性应用的除错、通用计算、系统控制和虚拟化技术等系统软件和通用应用程序等等。而GPU擅于处理规则数据结构和可预测存取模式。例如,光影处理、3D 坐标变换、油气勘探、金融分析、医疗成像、有限元、基因分析和地理信息系统以及科学计算等方面的应用。

AMD GPU在OpenCL下的存储体系
尽管在不少方面GPU表现优异,但在一段时间内,还会维持CPU与GPU各自发展的态势,它们可以继续在各自擅长的领域发挥作用,而未来的演进方向是相互取长补短,走向融合,而OpenCL正是它们融合与并行发展的连接桥梁。从CPU角度来讲,为了提高处理能力,以前是多线程,目前是多核,将来的发展方向是众核。
OpenCL的标准很大程度上决定了它的未来。获得整个计算机/视频硬件行业的支持也将起到帮助作用。从独立软件开发商的角度来看,OpenCL是通向混合(GPU/CPU)计算的大门。任何涉足高性能计算领域的人都会告诉你,在非标准的API上投入资金和时间是一项具有风险的业务,而OpenCL显然具备更大的潜力。

ATI Stream在Open CL下编程模型
CPU正向不断增加吞吐量和提高能效性的方向发展;而从GPU角度来讲,其可编程性能本来是在芯片内部固化的程序,然后发展到局部可编程,最后是完全可编程。也就是说,GPU是在提高所处理的吞吐量的同时,向通用处理的方向发展。作为一直在标准推广方面相对落后的AMD,本次借助OpenCL刚好可以实现更深层次的异构运算,其高端CPU甚至是未来整数性能极强的CPU会在OpenCL接口的帮助下,和高端GPU产品在异构模式下共处。而低端市场的APU产品,也会受益于OpenCL接口而支持更多应用,释放CPU和GPU的计算特性。

ATI Stream硬件通过Open CL获得了更为专业的支持
在今年6月,CAPS荣幸宣布其基于指令的混合编译器HMPP最新2.3版本已发布,内含OpenCL代码生成器。HMPP编译器集成了支持NVIDIA CUDA和OpenCL的强大数据并行后端,可极大缩短开发时间。OpenCL版HMPP完整支持AMD和NVIDIA GPU计算处理器,从而为广大混合计算应用开发者提供了广泛的程序开发支持。
Havok引擎与CPU+GPU异构运算
● Havok引擎与CPU+GPU异构运算
目前在游戏中应用最广的物理效果有粒子、流体、软体、关节和布料五大类,借助这些效果,我们的图形世界将会变得更加真实细致。从游戏发展的轨迹来看,大家都在力求一种“现实”的效果,从最1994年Doom Ⅱ那种粗糙的3D效果到2008年的Crysis,游戏的3D效果和光影效果都有了长足的进步。如何让游戏表现出更真实的一面,放在大家面前的有两条路。第一条就是增加特效,如DX8、DX9、DX10,这样的特效更多表现的是一种“静态”的效果。而另一条路则是增加如爆炸、布料摆动、关节运动等“动态”方面的真实效果。
物理运算有两大特点,第一是高并行度,第二是高运算密度,这两大特点刚好符合我们之前所分析的并行计算结构,所以从物理效果提出之时,人们就在寻找加速比更高的硬件解决方案来进行物理运算。AGEIA公司在GDC2005游戏开发者大会上推出了物理处理器PPU(Physics Processing Unit),被称为05年度图形领域的重大技术创新。这种芯片可以通过其内部的大量并行浮点处理器来运算物理特效,解放任务繁重的CPU。不过PPU的劣势就是需要附加运算卡才能实现,功能较为单一,整体实现成本方面也没有做到最优。

物理引擎发展的挑战与应对
随后使用GPU进行物理加速走进了人们的视野,GPU天生拥有较高的并行度,同时其内部可编程浮点单元能够执行物理运算。同时随着GPU内部结构不断完善,调度器、发射端和寄存器资源已经能够支撑GPU进行损失较小的上下文切换,这是GPU在执行图像渲染的同时进行物理加速工作的前提。而NVIDIA和AMD也都选择了相应的物理加速引擎为自己服务。
和现在广为人知的PhysX物理引擎相对的是AMD选择的Havok物理引擎,这是业界知名度最高的拥有广泛游戏资源支持的物理引擎。Havok发展到2005年的时候,已经可以在微软的视窗操作系统、Xbox与Xbox360,任天堂的GameCube与Wii、索尼的PS2、PS3与PSP、苹果电脑的Mac OS X、Linux等操作系统或游戏主机上使用。此游戏引擎是用C语言/C++语言所撰写而成。

AMD与Havok物理引擎始终保持密切合作
2006年,Havok物理引擎在基于CPU系统上获得众多支持的时候终于决定转向GPU系统,Havok FX引擎应运而生。Havok FX将物理运算分为特效和游戏运算,特效运算(如爆炸时的烟雾)将会由GPU的Shader Model 3.0来进行运算,进而减轻CPU的负担。而游戏物理运算则仍然由CPU处理。
但是随着Havok被Intel收购,基于GPU的物理引擎开发几乎陷入停滞。因为Intel当时的CPU发展思路已经转向了提高并行度,同时Intel程序中充满分支和循环嵌套的物理特效在GPU上难以完成,所以Intel让更多物理效果在CPU上运行。但是后期的GPU发展远超Intel预料,所以后期Havok还是和AMD不断合作谋求在GPU带来的更高加速比。

借助OpenCL接口Havok引擎开始异构计算
在GDC09展览中,演示中的Havok引擎使用了ATI的显示核心作为加速。由于引擎是基于OpenCL架构进行开发,所以处理器和显示核心都可以为其进行计算。基于GPU的Havok引擎发展,意味着AMD提倡多年的异构计算模式终于在更多领域找到了用武之地。虽然目前Havok引擎在GPU上的游戏数量少之又少,但是Havok引擎在CPU支持方面垄断了绝大部分游戏的物理加速接口。同时随着更多的CPU-GPU异构模式Demo推出,物理运算加速比相比纯GPU模式将会更好。
BOINC平台充沛的ATI GPU加速项目
● BOINC平台充沛的ATI GPU加速项目
如果你使用ATI显卡,不必去寻找那些高深的专业计算程序去体验GPU并行计算的魅力。体会ATI GPU的强大运算能力,只需加入BOINC平台就可以获得大量项目支持。从并行计算的分类层级来看,BOINC平台计算项目属于最高层级“集群或分布式计算”(Cluster/Distributed parallel)。
BOINC的中文全称是伯克利开放式网络计算平台(Berkeley Open Infrastructure for Network Computing),他能够把许多不同的分布式计算项目联系起来统一管理。并对计算机资源进行统一分配。BOINC目前已经成熟,多个项目已经成功运行于BOINC平台之上,如SETI@home、LHC@home、Rosetta@Home 、World Community Grid世界公共网格等。

BOINC分布式计算平台
MilkyWay@home是一个基于 BOINC 平台的分布式运算项目。项目试图精确构建银河系附近星流的三维动态模型。与 SETI@home 和 Einstein@home 相比较,MilkyWay@home 同样把探索星际空间作为项目目标。项目的另一个目标是开发并优化分布式计算的算法。该项目在今年年初已经汇聚了超过1PetaFlops运算能力,运算速度超过了世界上第二快的超级计算机,该项目在推出后不久就提供了支持ATI显卡的运算程序。
除了在计算机科学和天文学研究的重要发现外,研究人员表示,该项目对于公众的科学发现也作出了重要进展。自项目开始至今,来自 169 个国家超过 45000 名的志愿者捐献了计算能力,目前项目活跃的用户约有1.7万。除了志愿者外,伦斯勒其他学科及院外的机构也参与该项目。其中包括伦斯勒的研究生 Matthew Newby,Anthony Waters, Nathan Cole 还有 SETI@home的创始者David Anderson,这项研究的资金主要由国家科学基金会(NSF)提供,还有 IBM,ATI 和 NVIDIA捐献的设备。
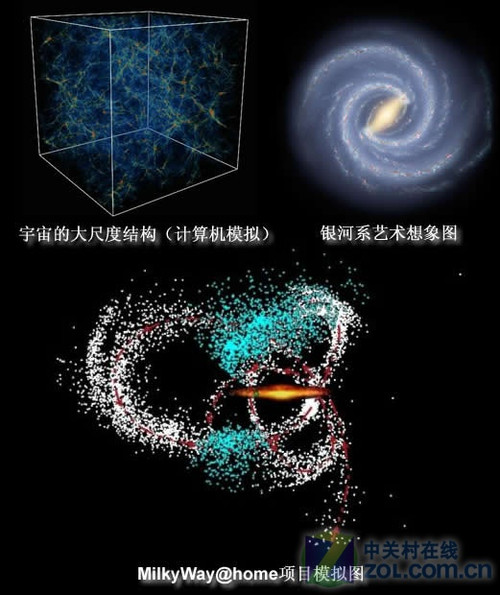
MilkyWay@home项目模拟(配图来自“科学松鼠会”《银河之伴,汝居何方》)
MilkyWay@home这个项目折射到计算机硬件方面,实际上就是像素对比,是对比进化算法得来的银河系演进图与真实拍得的照片的差异。它是按照进化算法先验算一个银河系在某时间断面的图,然后那这个图跟拍摄的实际照片进行对比。Milkyway@home虽然是研究天体的项目,但这种研究算法天生具有遗传算法的特性,其主要特点是直接对结构对象进行操作,不存在求导和函数连续性的限定;Milkyway@home提供的ATI显卡计算任务具有内在的隐并行性和更好的全局寻优能力,这个项目里更多的也不是分支嵌套,而是把算好的结果跟已知的观测结果进行比对,这样ATI GPU架构吞吐量巨大的优势再一次体现了。
另一个活跃在BOINC平台上的支持GPU计算的项目是Collatz Conjecture,这是一个利用联网计算机进行数学方面研究,特别是测试又称为3X+1或者HOTPO(取半或乘三加一)的考拉兹猜想的研究项目。该项目的运算目的很简单,变量只有一个n,如果它是奇数,则对它乘3再加1,如果它是偶数,则对它除以2,如此循环,最终都能够得到1。这个项目的研究目标就是寻找最大的质数。
该项目的主程序分支出现在初始段,而且所有的线程的分支几乎都是统一的,所以对于分支能力的考验是比较少的,反而它能够使几乎所有线程都同步进行这个相对简单的吞吐过程。这就决定了该项目上ATI GPU的运算速度要比NVIDIA GPU快,因为ATI所提供的硬件结构更适应于这种数据结构。

Radeon HD5770显卡正在运行DNETC@home项目的ATI加速任务
BOINC平台同样有一些密码学项目可以发挥ATI GPU的浮点加乘优势,比如在近期提供了GPU运算支持的DNETC@home项目。DNETC@HOME 是 distributed.net 在 BOINC 平台的封装器,用于使其平台的项目能够运行于 BOINC 平台上。Distributed.net 创立于1997年。2002年10月7日,以破解加密术而著称的 Distributed.net 宣布,在经过全球33.1万名电脑高手共同参与,苦心研究了4年之后,他们已于2002年9月中旬破解了以研究加密算法而著称的美国RSA数据安全实验室开发的64位密匙??RC5-64密匙。目前正在进行的是RC5-72密匙。
目前DNETC@home项目运行的是 RC5-72(试图攻破 RC5 的 72 位密钥)。值得一提的是项目没有提供 CPU 的计算程序,因此要参加项目必须使用显卡才能进行计算。
我们在第四章第六和第七节已经通过GPC Benchmark软件分析了ATI GPU在密码学计算中的优势。在DNETC@home项目这类密码学计算中,无论是加密还是解密都很少牵扯到计算层面,GPU只是不断随即生成数据然后去试探,决定运算结果的基本上只有开关(运算器)数量,而不是运算器组织结构,所以A卡理论吞吐量高的特性再次得到体现。
最具影响力的Folding@home项目
● 最具影响力的Folding@home项目
Folding@home是一个研究蛋白质折叠,误折,聚合及由此引起的相关疾病的分布式计算项目。我们使用联网式的计算方式和大量的分布式计算能力来模拟蛋白质折叠的过程,并指引我们近期对由折叠引起的疾病的一系列研究,找到相关疾病的发病原因和治疗方法。
Folding@home能了解蛋白质折叠、误折以及相关的疾病。目前进行中的研究有:癌症、阿兹海默症(老年失智症)、亨廷顿病、成骨不全症、帕金森氏症、核糖体与抗生素。

不同硬件为Folding@home项目提供的运算能力
您可以在斯坦福大学官方网页上下载并运行客户端程序,随着更多志愿者的计算机加入,此项目计算的速度就越快,就会计算出蛋白质在更长时间内的折叠,距离科学家找到最终答案也就越来越近。如果蛋白质没有正确地折叠将会使人得一些病症:如阿兹海默氏症(Alzheimers)、囊肿纤维化(Cystic fibrosis)、疯牛病(Mad Cow, BSE)等, 甚至许多癌症的起因都是蛋白质的非正常折叠。
Folding@home所研究的是人类最基本的特定致病过程中蛋白质分子的折叠运动。项目的核心原理在于求解任务目标分子中每一个原子在边界条件限制下由肽键和长程力等作用所导致的运动方程,进而达到实现模拟任务目标分子折叠运动的目的。每一个原子背后都附庸这若干个方程,每一个方程都可以转换成一组简单的向量指令。同时由于长程力的影响,条件分支也随处可见,Folding@home在GPU使用量上也要大于图形编程。
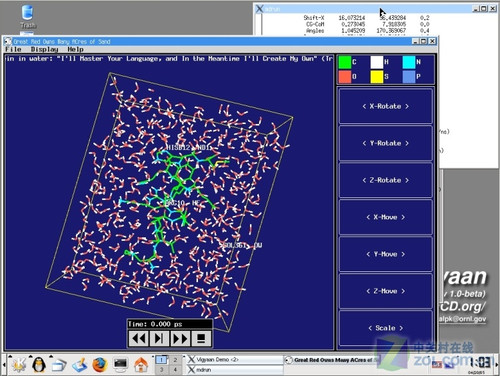
在分子动力学领域广泛使用的GROMACS引擎
由于针对不同的系统其代码进行了高度优化,GROMACS是目前最快的分子动力学模拟软件。此外,由于支持不同的分子力场以及按照GPL协议发行,GROMACS拥有很高的可定制性。GROMACS目前最新版本为4.07,可以到官方网站下载并自行编译。GROMACS支持并行/网格计算扩展,可灵活搭配MPI规范的并行运算接口,如MPICH、MPICH2、MPILAM、DeoinMPI等。国内也有很多分子动力专业人员同样使用GROMACS做研究,而且几乎是全部,GROMACS几乎成为模拟蛋白质折叠领域内的标准。
2006年9月底,ATI宣布了通用计算GPGPU架构,并得到了斯坦福大学Folding@Home项目的大力支持,加入了人类健康研究。2007年3月22日,PS3正式加入史丹佛大学分布式运算研究计划,至今已有超过百万名 PS3 玩家注册参与。NVIDIA于2008年6月宣布旗下基于G80及以上核心的显卡产品都支持该项目的通用计算,更是对分布式计算的重要贡献。

Radeon HD4870显卡正在运行Folding@home项目
Folding@home在自身定位明确、成功发展的基础下,通过斯坦福大学的大力推广,已经获得了全世界广泛认同。而近期PS3和GPU的参与更是将Folding@home的运算能力推向高峰。值得一提的是NVIDIA在2008年6月果断宣布加入Folding@home项目,至今已经为该项目提供了超过2 PFlops运算能力。
目前Folding@Home已经成为全世界最有影响力和公信力的项目,同时是各大厂商和机构鼎力支持的项目,当然它毫无疑问地拥有最广大的志愿者团队??截止2010年4月18日,全球共计1,396,683人参与该项目,最近的统计显示志愿者贡献的总运算能力已经达到了5PFlops,远超现在全世界最快的超级计算机IBM Roadrunner(最高性能1.026PFlops)。
该项目在中国拥有约2000多名参与者,其中最强大的China Folding@Home Power(Folding@Home中国力量,团队编号3213)团队已经拥有2585人,最近活跃用户200人以上,目前贡献计算量排名世界第47位,团队整体运算能力约为50到100TFLOPS。
GPU架构对于其他实例的适应性
● GPU架构对于其他实例的适应性
前文提到的几种GPU计算项目,都是一些非常直接具体的科学计算项目,它们是用户直接体会GPU计算的最简单途径。除此之外,还有大量实例可以在GPU上完成运算,特别是ATI提供的这种硬件架构可以在一些特殊运算中获得极高的加速比。
比如对于那些很难解决或者不可能精确求解的问题,蒙特卡洛算法提供了一种近似的数值解决方法。蒙特卡洛仿真与生俱来的特征就是多次独立重复实验的使用,每次独立实验都有某些随机数驱动。根据大数定律,组合的实验次数越多,最后得到的平均答案就越接近于真实的答案。每次重复实验天生就具有较强的并行特征,而且它们通常由密集数操作组成,因此GPU几乎为蒙特卡洛仿真提供了一个完美的平台。
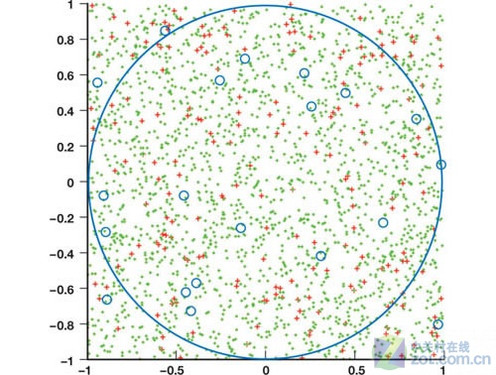
使用蒙特卡洛算法在正方形内计算π
使用蒙特卡洛算法解决问题的一个简单例子是计算π的值。这需要首先绘制出一个正方形,然后绘制它的内切圆。如果圆的半径是r,圆的面积就是πr2,而外接正方形的面积就是4r2。如果可以计算出圆面积和正方形面积之间的比例系数p,就可以计算π了。使用蒙特卡洛算法在正方形内均匀地生成n个独立的随机点,假设这些点中有k个位于园内,则p≈k/n,既π≈4k/n。点数分布越多,π的值精度就越高,当n=2×104及2×105时得到的近似值分别为3.1492和3.1435。
很明显这种计算π的方法效率很低,因为它的精度增长率很低(精度通常和实验次数的平方根成正比),而且比标准重复方法效率低了很多。然而它却说明了蒙特卡洛算法为何如此盛行的原因:1、该方法通常不是问题应对的精确解决方法,很容易理解它的工作原理。2、只要运算资源充沛,该方法通常容易实现,障碍只是随机数生成。3、蒙特卡洛算法天生就是并行的。其中最后一点正说明了蒙特卡洛算法很容易在网络集群中的多个节点上运行,或者在一个CPU或者GPU内的多个处理器上运行,该算法通用性极强,比如它允许我们为很多没有分析型方案的金融模型寻找解决方案。
第二个要介绍的例子是使用GPU进行Nbody仿真。它在数值上近似地表示一个多体系统的演化过程,该系统中的一个体(Body)都持续地与所有其他的体相互作用。一个相似的例子是天体物理学仿真,在该仿真中,每个体代表一个星系或者一个独立运行的星系,各个体之间通过万有引力相互吸引,如图所示。在很多其他计算机科学问题中也会用到N-body仿真,例如蛋白质折叠就用到Nbody仿真计算静电荷范德华力。其他使用Nbody仿真的例子还有湍流流场仿真与全局光照计算等计算机图形学中的问题。

DirectX 11 SDK Nbody Gravity测试项目
在NVIDIA最初G80架构的Geforce 8800GTX GPU上计算每秒100多亿个引力系统的性能,这个成绩是一个经过高度优化的CPU实现的性能的50多倍。Nbody仿真问题的研究贯穿了整个计算科学的历史。在20世纪80年代,研究人员引进了分层和网格类型的算法,成功降低了计算复杂度。自从出现了并行计算机,Nbody仿真的并行化也开始被研究了。同时从CPU到GPU的现有研究成果不仅仅是为了降低运算的功耗,还可以降低分层度,节省远域计算的时间。
N Body Gravity测试具备两个显著的特点,首先是高并行度,该测试拥有大量相互碰撞的粒子,粒子之间会产生复杂而又数量较多的力量变化。同时该测试拥有较高的运算密度,GPU在处理此类问题时可以有效展现其强大的并行运算能力。
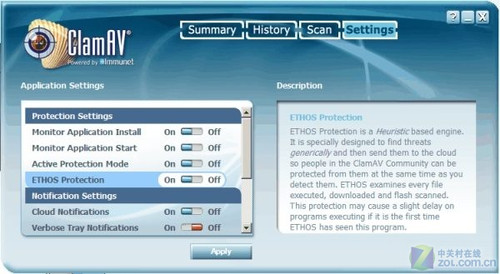
利用开源的杀毒软件ClamAV来基于GPU进行病毒检测
GPU还可以作为一个高速过滤器,来检验计算机病毒,这一原理和MilkyWay@home项目的像素对比有异曲同工之处。作为一个并行数据处理器,GPU擅长于处理那些具有常规的、固定大小的输入输出数据集合的算法任务。因为通过让CPU处理变长的和串行的任务,而GPU处理并行度较高的任务,可以最大限度地利用GPU进行病毒检测。GPU可以使用很少的字节来确定是否可能与数据库中的某个特征匹配,然后GPU再确认所有的匹配。
全文总结与未来架构展望
● 全文总结与未来架构展望
作为本世纪初计算机行业的最大变革,GPU所能处理的任务已经远超图形界限。通过全文分析,相信用户已经了解到了AMD在并行计算技术方面的发展历程和现状,无论是通过Stream技术将GPU用于高性能并行计算领域,还是通过计算机内的CPU-GPU异构模式来完成更多任务,AMD都在努力为用户提供更全面效率更高的解决方案。
关于未来硬件和应用环境的适用方面,Intel是从CPU往中间走,NVIDIA是从GPU往中间走,AMD则是直接空降到了中间。Intel的CPU产品所代表的是极强的逻辑控制包括分支循环等能力和单线程处理能力,ATI和NVIDIA的GPU产品代表的是极强的数据吞吐和并行任务能力。在这两者中间,是目前高性能计算和未来的图形计算所需求的应用,也是AMD想通过CPU-GPU异构计算和Fusion所达到的目标??更为强大的分支仲裁能力和更高的并行度。让我们共同期待在CPU和GPU技术领域长期蛰伏的AMD能借助融合之势回到巅峰状态。

CPU和GPU都在演变过程中
回到我们现在所处的编程环境来考虑,Fusion所提出的融合概念是一条非常好的解决途径。从绝对性能角度来考虑,AMD目前没有最好的CPU,ATI又没有最好的GPU,但是它可能将来会有最好的运算解决方案。而在Intel这边Larrabee还没有放弃,反而加速了。尤其是看到了Fermi之后,Intel更加确信自己的路并没有错。
但是目前的CPU加GPU分离式异构结构并不是万灵药,它需要更复杂的节点设置和控制,还有存储以及更加特异的任务拆解方式。而融合刚好可以很大幅度的消减异构带来的影响,融合不光是成本,还有整个系统的复杂度都可以得到有效降低。当然确实想要真正融合的话,必须要有对应的指令集。
从经济学角度讲,AMD这种直接放流处理器单元进入CPU逻辑的方法相对于开发新的指令集来的更快。AMD所提出的融合的确是个很好的方向,它能够绕开控制型结构,直接给核心提供现成的运算单元。使用这种简易直接的融合方式可以在高性能计算和并行计算领域为AMD赢得一块领地,而长远考虑仍然需要优秀的指令集和更为深层次的融合方式。
融合与异构或许都能够受惠于Intel提出的全新AVX指令集。这种指令集可大大提高浮点、媒体和处理器密集型程序的性能,重点在于AVX从当前的128bit向量指令增加到256bit的向量指令。作为Sybridge架构中的一个重要属性,AVX指令集可以大幅提升处理器的浮点运算功能,或许也能成为不同硬件逻辑融合的接口。
今后一段时间内,CPU+GPU的异构计算结构将引领处理器的发展方向,这也成为下一代超级计算的发展方向,而融合还需要不断改进和成熟。目前设计GPU+CPU架构平台的指导思想是:让CPU的更多资源用于缓存,GPU的更多资源用于数据计算。把两者放在一起,不但可以减小在传输带宽上的花销,还可以让CPU和GPU这两个PC中运算速度最快的部件互为辅助。
在文章末尾特别感谢艾维硕科技媒体公关经理,朱亮先生。从我策划这篇文章开始,他就为本文提供了重要的参考资料支持,文中有很多准确辅助内容的配图正是来自这些资料。
本文参考与引用文献:
[1] 《定分止争-细研GPU架构流程工作原理》
[2] 《高性能运算之CUDA》 第一章 GPU通用计算
[3] 《高性能并行计算》 并行计算机发展历程
[4] 《Introduction to Parallel Computing》What is Parallel Computing
[5] 《Introduction to Parallel Computing》Flynns Classical Taxonomy
[6] 《流处理器缘何差6倍 A/N GPU架构解析》
[7] 《ATI Radeon™ HD 5800 Series Graphics》
[8] 《图形硬件与GPU体系结构》
[9] 《GPUs - Graphics Processing Units》Introduction
[10]《ATI Xenos: XBOX360 GPU》